WorldRFT 계획‑중심 잠재 세계 모델로 안전한 자율주행 실현
초록
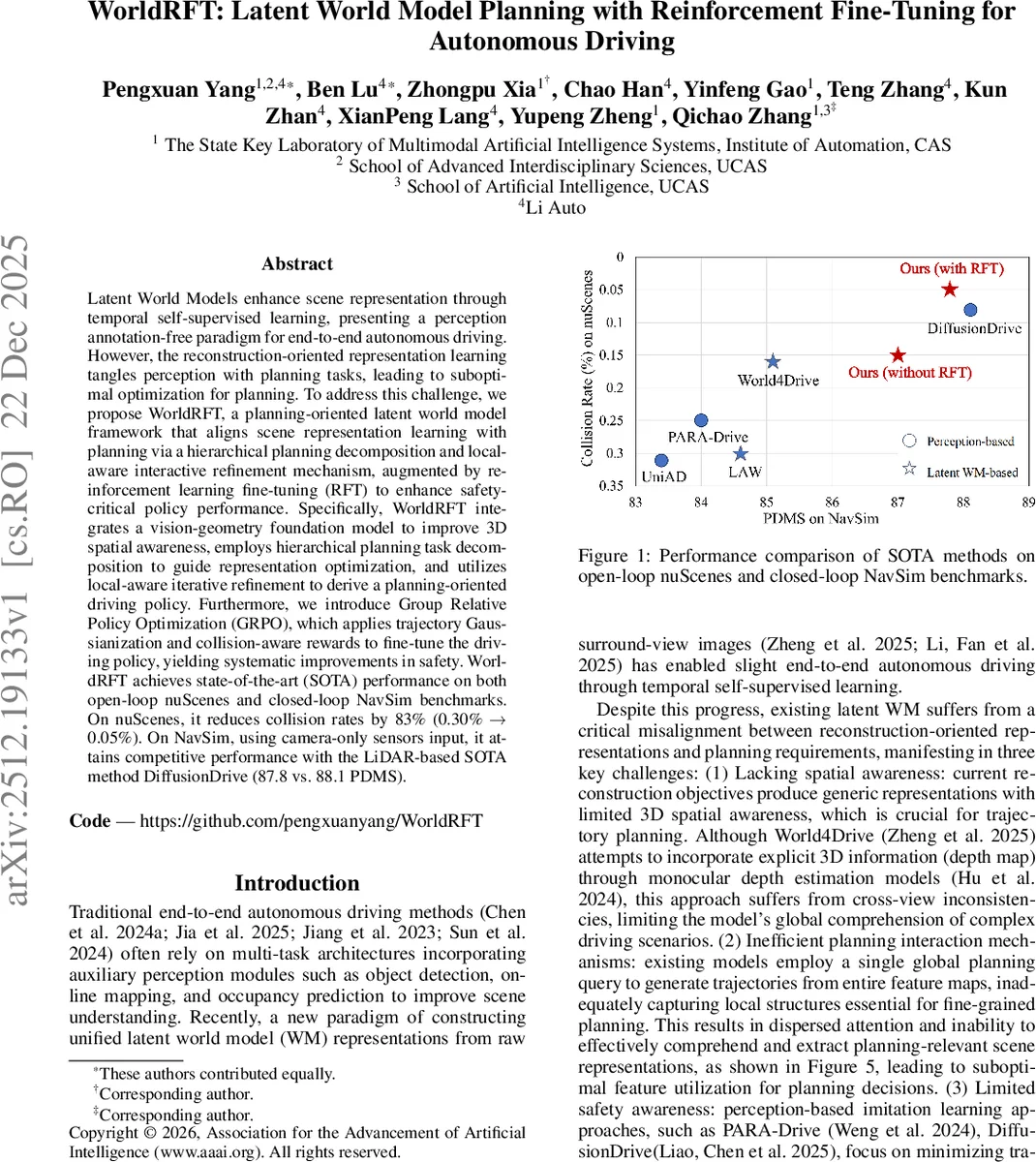
WorldRFT는 시각‑기하학 기반의 잠재 세계 인코더와 계층적 계획 분해, 지역‑인식 반복 정제, 그리고 충돌‑인식 보상으로 강화학습 미세조정을 결합한 프레임워크이다. 3D 공간 인식을 강화하고, 전역‑지역 정보를 효율적으로 교환하며, 안전 목표를 명시적으로 최적화함으로써 nuScenes와 NavSim 벤치마크에서 충돌률을 83 % 감소시키고, 카메라‑전용 설정에서도 LiDAR 기반 최첨단 모델에 근접한 성능을 달성한다.
상세 분석
WorldRFT는 기존 잠재 세계 모델(Latent World Model, WM)이 재구성 손실에 의존해 인코딩된 표현이 계획 단계와 불일치한다는 근본적인 한계를 짚고, 이를 해결하기 위한 네 가지 핵심 설계 요소를 제시한다. 첫째, VGGT라는 비전‑기하학 기반 파운데이션 모델을 frozen 상태로 활용해 2D 주변 이미지에서 3D 토큰을 추출하고, 이를 Cross‑Attention을 통해 일반적인 2D 비전 피처와 융합한다. 이 과정에서 명시적인 깊이 지도 없이도 다뷰 일관성을 유지하면서 3D 공간 인식을 강화한다는 점이 혁신적이다. 둘째, 계획을 ‘목표 영역 로컬라이제이션’, ‘공간 경로 플래닝’, ‘시간적 궤적 예측’이라는 세 개의 병렬 서브태스크로 계층화한다. 각 서브태스크는 전용 쿼리를 갖고, Cross‑Attention으로 잠재 세계 표현을 집계한 뒤, Self‑Attention 기반의 쿼리 결합을 통해 상호 의도를 공유한다. 이는 전역 플래닝 의도를 유지하면서도 서브태스크별 특화된 정보를 효율적으로 추출한다는 장점이 있다. 셋째, 지역‑인식 반복 정제(Local‑aware Iterative Refinement) 모듈은 초기 계획 결과(목표 중심 µ와 스케일 b, 공간 경로, 시간 궤적)를 반복적으로 업데이트한다. 각 반복 단계에서 궤적을 카메라 파라미터로 투영하고 Deformable Convolution으로 해당 위치의 로컬 피처를 샘플링한다. 여기서 b(불확실성 스케일)는 지역 피처와 전역 플래닝 의도를 가중합하는 조절 신호로 작용해, 복잡한 상황일수록 더 넓은 탐색을 허용한다. 마지막으로, 강화학습 미세조정 단계에서는 Group Relative Policy Optimization(GRPO)을 도입한다. 궤적을 Gaussian 분포로 변환해 탐색성을 확보하고, ‘거리 기반 충돌 보상’과 ‘스케일‑가중 충돌 보상’을 설계해 안전성을 직접 최적화한다. 특히, 기존 행동 복제(Imitation Learning) 방식이 모든 편차를 동일하게 취급하던 것을 넘어, 충돌 위험을 명시적으로 페널티화함으로써 ‘능동적 회피’를 학습한다. 실험 결과는 nuScenes 오픈‑루프 평가에서 평균 변위 오차(ADE)를 21 % 감소시키고, 충돌률을 0.30 %→0.05 %로 83 % 낮추는 등 안전 지표에서 현저한 개선을 보여준다. 또한 NavSim 닫힌‑루프 시뮬레이션에서는 카메라‑전용 입력만으로 PDMS 87.8점을 기록, LiDAR 기반 DiffusionDrive(88.1점)에 근접한다. 전반적으로 WorldRFT는 ‘표현‑계획‑안전’ 삼위일체를 설계 단계부터 일관되게 맞춤화함으로써, 기존 WM 기반 자율주행 시스템이 겪던 재구성‑계획 불일치를 근본적으로 해소한다는 점에서 학술적·실용적 의의가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기