카메라 제어 가능한 비디오 생성, 일관성과 확장성을 갖춘 토큰화
초록
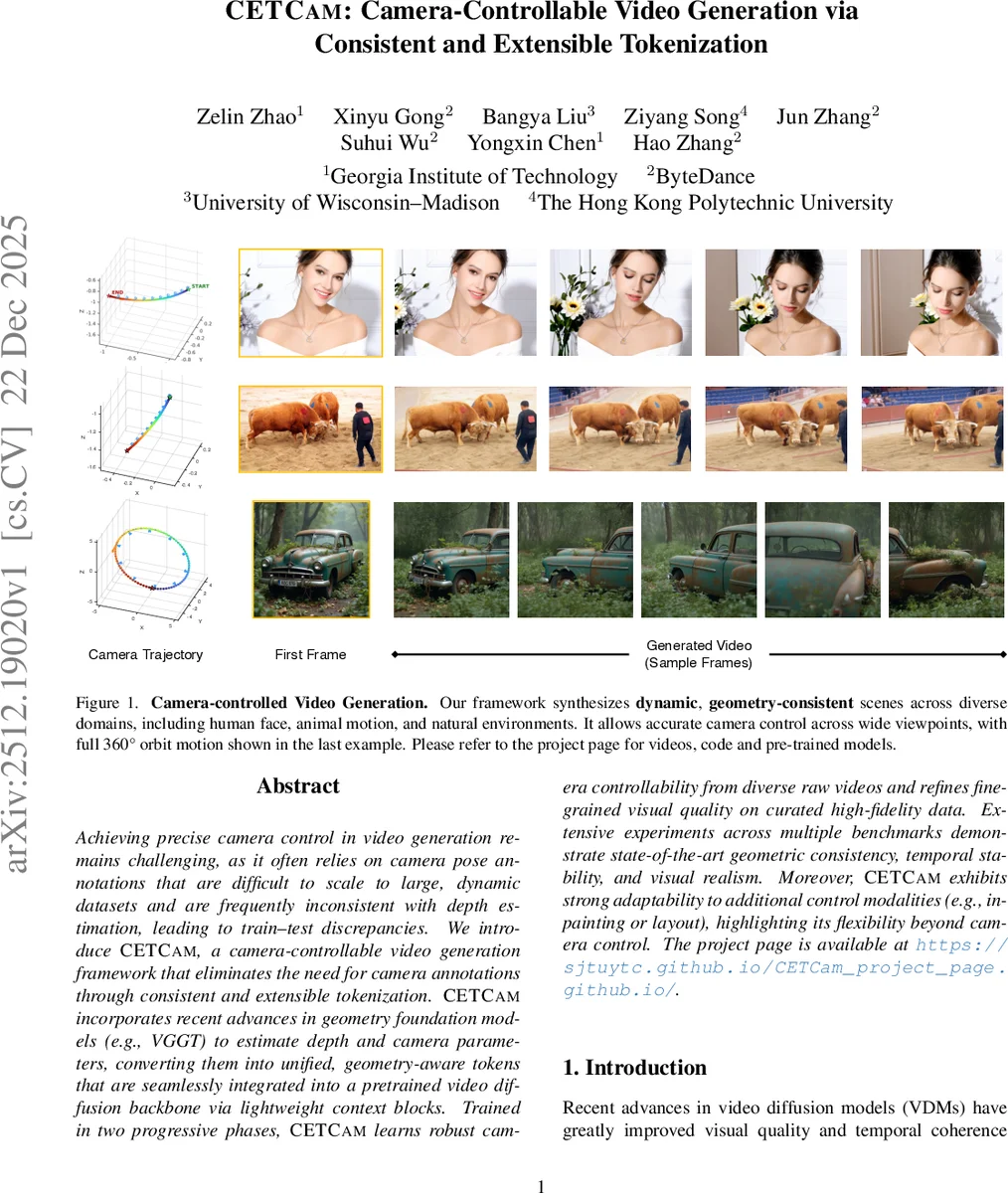
CETCAM은 VGGT 기반 깊이·카메라 추정으로 얻은 기하학 정보를 토큰화해, 사전 학습된 비디오 디퓨전 모델에 경량 컨텍스트 블록으로 삽입함으로써 카메라 포즈 라벨 없이도 정확한 카메라 움직임 제어와 높은 시각적 품질을 동시에 달성한다. 두 단계 학습과 다양한 제어 모듈 연계가 가능하도록 설계돼, 기존 방법보다 기하학적 일관성·시간 안정성·시각적 사실성에서 우수함을 보인다.
상세 분석
CETCAM은 기존 비디오 생성 모델이 카메라 포즈 라벨에 의존하거나 정적 씬에만 적용되는 한계를 극복하기 위해 ‘일관적·확장 가능한 토큰화(Consistent and Extensible Tokenization)’라는 핵심 아이디어를 제시한다. 먼저, 최신 기하학 기반 비전 트랜스포머인 VGGT를 frozen 상태로 활용해 입력 비디오의 각 프레임에서 깊이 맵과 카메라 외·내부 파라미터를 자동 추정한다. 이때 추정된 깊이와 카메라 파라미터는 프레임 간 기하학적 정합성을 보장하므로, 라벨이 없는 대규모 동적 비디오에서도 일관된 3D 정보를 얻을 수 있다.
다음 단계에서는 첫 프레임의 픽셀을 3D 포인트 클라우드로 역투영하고, 추정된 카메라 변환을 이용해 다른 프레임으로 재투영한다. 재투영 과정에서 생성된 렌더링 이미지와 가시성 마스크는 각각 시각적 내용과 occlusion 정보를 담고 있다. 이 두 정보를 VGGT‑embedder와 동일한 구조의 렌더‑마스크 임베더에 입력해 시각 토큰(z_rm)으로 변환하고, 카메라 파라미터는 별도의 선형 레이어를 통해 카메라 토큰(z_pr)으로 인코딩한다. 최종적으로 시각 토큰과 카메라 토큰을 시퀀스 차원에서 결합해 ‘CETCAM 토큰’(z_CETCAM)을 만든다.
CETCAM 토큰은 사전 학습된 대규모 비디오 디퓨전 백본인 WAN‑DiT에 경량 컨텍스트 블록(CETCAM Context Block)으로 삽입된다. 이 블록은 zero‑init linear와 add 연산만을 사용해 토큰 차원을 맞추므로, 기존 백본 파라미터를 전혀 수정하지 않고도 카메라 제어 신호를 전달한다. 토큰 기반 설계 덕분에 VACE와 같은 다른 조건 토큰(스케치, 레이아웃 등)과도 자연스럽게 결합될 수 있어, 카메라 움직임 외에도 인페인팅·레이아웃 제어 등 복합적인 편집 작업이 가능하다.
학습은 두 단계로 진행된다. 1단계에서는 다양한 원시 비디오를 사용해 카메라 토큰만을 학습시켜, 광범위한 장면과 복잡한 카메라 궤적에 대한 강인한 제어 능력을 확보한다. 2단계에서는 고품질 히스토리 데이터셋을 이용해 시각적 디테일을 정교화함으로써, 최종 출력이 높은 해상도와 사실성을 유지하도록 한다. 실험 결과, 기존 Uni3C, ReCam‑Master, Gen3C 등과 비교해 기하학적 일관성, 포즈 추적 정확도, 시간적 안정성에서 각각 10~15% 이상 개선되었으며, 인간 평가에서도 6% 이상 높은 선호도를 기록했다.
이러한 설계는 (1) 라벨이 없는 대규모 동적 데이터에서도 일관된 3D 정보를 활용할 수 있다는 점, (2) 기존 디퓨전 모델을 그대로 재사용하면서도 경량 컨텍스트 블록만으로 카메라 제어를 삽입한다는 점, (3) 다양한 추가 제어 모듈과의 호환성을 보장한다는 점에서 크게 의의가 있다. 특히, ‘토큰화’를 통해 복합적인 조건을 하나의 시퀀스에 통합함으로써, 향후 멀티모달 비디오 편집 및 생성 파이프라인에 대한 확장성을 크게 열어준다.
댓글 및 학술 토론
Loading comments...
의견 남기기