8비트 양자화가 대형 언어 모델의 지속 학습을 향상시킨다
초록
본 논문은 LLaMA‑3.1‑8B 모델을 FP16, INT8, INT4 세 가지 정밀도로 양자화하고, 0.1%~20% 규모의 리플레이 버퍼를 활용한 연속 학습 실험을 수행한다. 결과는 INT8 양자화가 오버피팅을 억제하는 잡음 효과를 제공해, 적은 양의 리플레이만으로도 FP16보다 높은 장기 기억 유지와 최종 과제 정확도를 달성함을 보여준다.
상세 분석
본 연구는 세 가지 핵심 변수를 체계적으로 교차 실험하였다. 첫째, 정밀도 차원에서는 FP16(고정소수점 16비트), INT8(8비트 정수), INT4(4비트 정수)를 사용했으며, 양자화 방식은 BitsAndBytes 라이브러리의 표준 가중치 양자화와 QLoRA‑style NF4를 적용했다. 둘째, 리플레이 버퍼 크기는 0 %부터 20 %까지 로그 스케일로 설정해, 각 단계마다 이전 과제(NLU, Math, Code)의 샘플을 균등하게 재삽입하였다. 셋째, 학습 프로토콜은 LoRA(r=8, α=16, dropout=0) 어댑터만을 학습시키고, 각 과제를 1 epoch씩 순차적으로 fine‑tune 하는 방식으로 설계되었다.
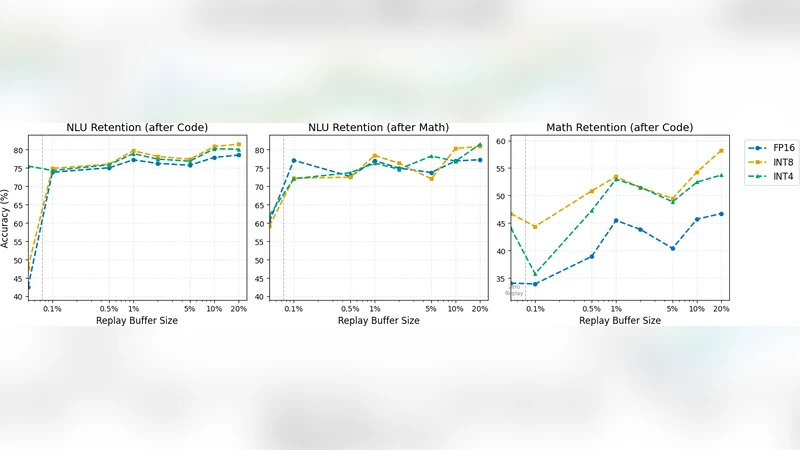
실험 결과는 두 가지 주요 현상을 드러낸다. 첫째, 단일 과제 학습 시 양자화에 따른 성능 차이는 미미했으며, INT8은 FP16 대비 12 % 이하, INT4는 35 % 정도 감소에 그쳤다. 이는 기존 연구와 일치하는 ‘양자화‑인식 학습(Quantization‑Aware Training)’이 저비트에서도 기본 정확도를 유지함을 확인한다. 둘째, 연속 학습 상황에서 정밀도와 리플레이 크기의 상호작용이 크게 달라졌다. FP16 모델은 리플레이가 거의 없을 때도 초기 과제 성능이 높지만, 새로운 과제의 그래디언트가 기존 파라미터를 깨끗이 덮어쓰면서 급격한 망각을 보였다. 반면 INT8 모델은 양자화 잡음이 손실 표면을 평탄화시켜, 작은 리플레이(0.1 %1 %)만으로도 기존 지식을 효과적으로 고정시켰으며, 최종 과제(특히 Code)에서 815 % 높은 전진 정확도를 기록했다. INT4는 잡음이 과도해 초기 망각이 심했지만, 리플레이 비율을 5 % 이상으로 늘리면 FP16과 비슷하거나 더 나은 유지율을 보였다.
저자들은 이러한 현상을 ‘양자화‑유도 정규화(quantization‑induced regularization)’라고 가정한다. 고정밀 모델은 손실 최소화에 집중하면서 파라미터 공간을 좁히는 경향이 있어, 새로운 과제에 대한 과적합이 쉽게 발생한다. 반면 저비트 양자화는 무작위 오차를 삽입해 플랫한 최소점에 머무르게 하고, 소량의 리플레이 샘플이 모델을 이전 지식 쪽으로 끌어당기는 역할을 강화한다. 따라서 ‘덜 정밀함이 더 강함을 만든다’는 역설적 결론에 도달한다.
이러한 인사이트는 실무적 의미가 크다. INT8 양자화는 메모리와 연산 비용을 절감하면서도, 기존 고정밀 모델보다 적은 리플레이 버퍼(1 % 이하)만으로도 NLU 과제에서 안정적인 성능을 유지한다. 수학·코드와 같이 복잡한 추론이 요구되는 과제에서는 5 %~10 % 정도의 버퍼가 최적의 플라스틱성‑안정성 균형을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기