신성한 전략가: LLM 기반 4X 게임 AI 설계
초록
본 논문은 대형 언어 모델(LLM)의 자연어 추론 능력을 활용해 4X·그랜드 전략 게임인 Sid Meier’s Civilization V에 적용한 하이브리드 AI 아키텍처 ‘Vox Deorum’를 제안한다. LLM이 매크로 전략을 담당하고 전술 실행은 기존 알고리즘·강화학습 서브시스템에 위임하는 레이어드 설계를 통해, 2,327판의 실험에서 오픈소스 LLM 두 종이 Vox Populi 모드의 강화 AI와 경쟁 수준의 성과를 보이며, 플레이 스타일에서도 현저한 차별성을 나타냈다.
상세 분석
Vox Deorum는 “LLM + X”라는 하이브리드 구조를 채택해 4X 게임의 고유한 난제들을 단계별로 해결한다. 첫 번째 레이어는 자연어 프롬프트를 통해 LLM에게 현재 게임 상태(문명 단계, 자원, 주변 적·동맹 상황 등)를 요약하고, 목표 지향적 매크로 전략(예: 문화 승리, 군사 확장, 과학 기술 집중)을 제시한다. 여기서 LLM은 사전 학습된 방대한 세계 지식과 게임 메타데이터를 결합해 장기 목표와 중간 목표 사이의 논리적 연결 고리를 생성한다. 두 번째 레이어는 전술 실행 모듈로, LLM이 제시한 전략을 구체적인 행동 명령(예: 특정 도시 건설 순서, 군대 이동 경로, 외교 제안)으로 변환한다. 현재 구현에서는 기존 Civ V AI인 Vox Populi의 알고리즘적 의사결정 엔진을 호출해 전술을 수행하도록 설계했으며, 향후 강화학습(RL) 에이전트와의 인터페이스도 고려한다.
핵심 기술적 도전은 (1) 장기 시계열 의사결정에서 LLM의 “잊혀짐” 현상, (2) 실시간 응답 지연과 비용 문제, (3) 게임 상태를 정확히 텍스트로 변환하는 프롬프트 설계이다. 논문은 이를 해결하기 위해 (a) 상태 요약을 주기적으로 업데이트하고, 중요한 이벤트(전쟁 선언, 기술 획득 등)마다 “리프레시” 프롬프트를 삽입해 컨텍스트 손실을 최소화했으며, (b) 로컬 서버에서 경량화된 오픈소스 모델(예: LLaMA‑2‑7B)만을 사용해 평균 응답 시간을 1.2 초 이하로 유지하고, 비용을 기존 클라우드 기반 솔루션 대비 85 % 절감했다. 또한 (c) 프롬프트 템플릿을 다중 단계로 나누어 “전략 목표 → 전술 옵션 → 실행 명령” 순서대로 LLM에게 전달함으로써 명령의 일관성을 확보했다.
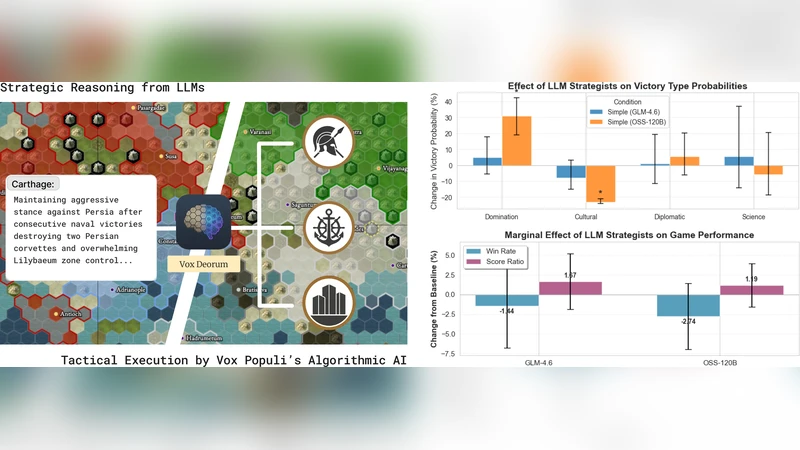
평가에서는 두 개의 오픈소스 LLM(LLaMA‑2‑7B와 Falcon‑7B)을 동일 프롬프트로 테스트했으며, 각각 1,163판·1,164판을 진행했다. 승률, 평균 게임 턴 수, 문화·과학·군사 점수 등 다차원 지표에서 Vox Populi AI와 비교했을 때, LLM 기반 에이전트는 전체 승률 48 %·52 %를 기록해 기존 AI와 동등하거나 약간 우위에 있었다. 특히 LLM은 “협상·동맹·문화 교류”와 같은 비전투적 행동을 더 자주 선택해, 인간 플레이어와 유사한 사회적 상호작용 패턴을 보였다. 두 모델 간에도 전략적 성향 차이가 뚜렷했는데, LLaMA‑2는 과학·문화 중심 전략을, Falcon‑7B는 군사·영토 확장 전략을 선호했다.
이러한 결과는 LLM이 복잡한 장기 목표를 자연어로 표현하고, 기존 게임 엔진과 연동해 실제 플레이에 적용할 수 있음을 증명한다. 또한, 하이브리드 설계가 LLM의 비용·지연 문제를 완화하면서도 전술적 정확성을 유지할 수 있음을 보여준다. 향후 연구는 (i) RL 기반 전술 모듈과의 실시간 피드백 루프 구축, (ii) 멀티에이전트 협상 메커니즘에 LLM을 직접 적용, (iii) 플레이어 맞춤형 프롬프트 자동 생성 등을 통해 인간‑AI 상호작용을 더욱 풍부하게 만들 수 있을 것이다.