ReX MLE 의료영상 자동코딩 에이전트 벤치마크
초록
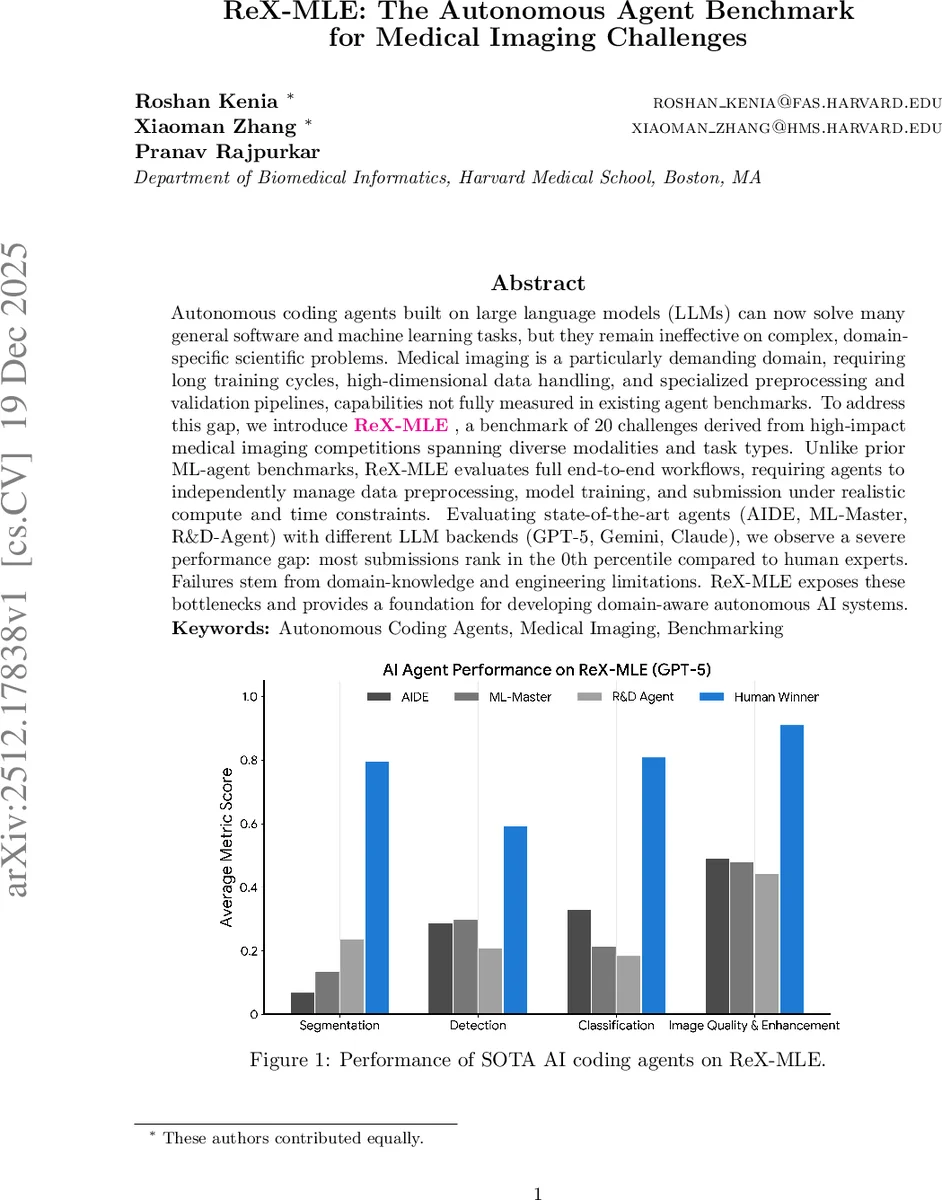
ReX-MLE는 20개의 고난이도 의료영상 대회 과제를 모아 만든 벤치마크로, 자동 코딩 에이전트가 데이터 전처리·모델 학습·제출까지 전 과정을 독립적으로 수행하도록 평가한다. 최신 LLM 기반 에이전트(GPT‑5, Gemini, Claude)를 적용한 실험 결과, 인간 전문가 대비 0 % 수준의 성적을 기록하며 도메인 지식과 엔지니어링 역량의 한계를 드러낸다.
상세 분석
본 논문은 의료영상이라는 특수 분야가 요구하는 고차원 데이터 처리, 장시간 학습, 복잡한 전처리·후처리 파이프라인이 기존 자동코딩 에이전트 벤치마크에 충분히 반영되지 않았음을 지적한다. 이를 보완하기 위해 저자들은 Grand Challenge에서 선정된 20개의 과제를 8가지 모달리티(CT, MRI, MRA, 초음파, 병리학, 현미경 등)와 4가지 작업 유형(분할, 검출, 분류, 이미지 생성)으로 구성한 ReX‑MLE를 설계하였다. 각 과제는 실제 대회와 동일한 데이터 포맷(NIfTI, JSON 등)과 평가 스크립트를 제공하며, 에이전트는 24시간·H100 GPU 1대라는 현실적인 컴퓨팅·시간 제한 하에 전 과정을 자동화해야 한다.
실험에 사용된 세 가지 에이전트는 각각 다른 탐색·학습 전략을 갖는다. AIDE는 그리디 트리 탐색 기반 코드 최적화, ML‑Master는 몬테카를로 트리 서치를 통한 다중 경로 탐색, R&D‑Agent는 연구자·개발자 모듈을 분리한 이중 에이전트 구조다. 모든 에이전트는 동일한 하드웨어와 GPT‑5를 기본 LLM으로 사용했으며, 일부 실험에서는 솔루션 보고서(‘w/ sol.’)를 제공해도 성능 향상이 미미했다.
성능 평가 결과, 인간 최고 점수와 비교했을 때 대부분의 과제에서 0 % 백분위에 머물렀다. 특히 고차원 3D CT·MRI 분할, 병리학 슬라이드 검출 등에서는 Dice, mAP, IoU 점수가 거의 0에 수렴했으며, 이는 에이전트가 데이터 로딩·정규화·증강 단계에서 기본적인 오류를 범했음을 의미한다. 반면 비교적 단순한 2D 병리학 분류(HCD)에서는 ML‑Master가 인간 수준에 근접한 AUC 0.992를 달성했지만, 이는 전체 성능을 대표하기엔 한계가 있다.
추가로 저자들은 13가지 ‘Winning Strategies’를 기준으로 자동 LLM‑judge 파이프라인을 구축해 각 에이전트의 전략 실행 여부를 이진화하였다. 결과는 대부분의 에이전트가 ‘데이터 탐색·전처리 설계·하이퍼파라미터 튜닝·디버깅·재현성 검증’ 등 핵심 과정을 거의 수행하지 못했음을 보여준다. 즉, 현재 LLM 기반 자동코딩 에이전트는 아이디어 생성·코드 자동완성 수준에 머물러 있으며, 실제 의료영상 파이프라인을 운영·조정하는 엔지니어링 역량이 현저히 부족하다.
이러한 분석을 통해 논문은 두 가지 주요 시사점을 제시한다. 첫째, 도메인‑특화 데이터 처리와 장시간 학습을 지원하는 새로운 프롬프트 설계·메모리 관리 기법이 필요하다. 둘째, 에이전트가 인간 전문가와 동일한 수준의 실험 설계·결과 검증 과정을 수행하도록 ‘self‑debugging’·‘resource‑aware planning’ 메커니즘을 통합해야 한다. ReX‑MLE는 이러한 연구 방향을 검증할 수 있는 표준 테스트베드로서, 향후 도메인‑인식 자동 AI 시스템 개발에 핵심적인 역할을 할 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기