추론 팔레트: 잠재 컨텍스트로 전략적 탐색 제어
초록
본 논문은 대형(비전)언어 모델의 추론 다양성을 높이기 위해, 질문‑답변 쌍의 평균 풀링 임베딩을 VAE로 압축한 잠재 변수를 샘플링하고, 이를 토큰 프리픽스로 디코딩해 입력 앞에 삽입함으로써 내부 계획을 사전 조정한다. 짧은 SFT 단계 후 RL 학습에 적용하면 탐색 효율과 성능이 크게 향상된다.
상세 분석
Reasoning Palette는 기존 LLM/VLM이 토큰 수준의 확률적 디코딩에 의존해 고수준 전략 다양성을 확보하지 못한다는 문제를 근본적으로 해결한다. 핵심 아이디어는 질문‑답변 쌍을 평균 풀링해 얻은 고정 차원의 임베딩 h를 VAE의 인코더에 입력, 평균‑분산 파라미터(µ,σ)를 추정해 가우시안 잠재 z를 샘플링한다는 점이다. 이 잠재는 “추론 컨텍스트”를 의미하며, 디코더 Dψ가 z를 다시 임베딩 공간으로 복원해 L개의 연속 프리픽스 임베딩 p_z를 생성한다. p_z는 기존 토큰 임베딩과 동일한 차원을 가지므로, 사전 훈련된 모델에 별도 구조적 변경 없이 그대로 삽입할 수 있다.
SFT 단계에서는 사전 훈련된 모델이 임의의 프리픽스에 적응하도록, VAE 디코더가 만든 p와 원본 질문‑답변 쌍을 결합한 데이터셋을 짧게(10 이터레이션 정도) 미세조정한다. 이 과정은 모델이 프리픽스에 과도히 의존하거나 일반화 능력을 상실하는 것을 방지한다.
RL 단계에서는 매 에피소드마다 새로운 z를 샘플링해 프리픽스를 삽입함으로써, 정책이 동일한 질문에 대해 서로 다른 “추론 전략”을 탐색하도록 만든다. 이는 토큰‑레벨 무작위성보다 높은 수준의 구조적 다양성을 제공해, 특히 희소하고 검증 가능한 보상이 사용되는 RL‑VR 환경에서 탐색 효율을 크게 높인다. 또한, 잠재 공간이 연속적이고 의미론적으로 구분되도록 β‑VAE와 KL 정규화를 활용했기 때문에, 특정 전략(예: 수학적 증명, 코드 디버깅)과 연관된 영역을 사후 분석하거나 목표 지점으로 편향 샘플링하는 것이 가능하다.
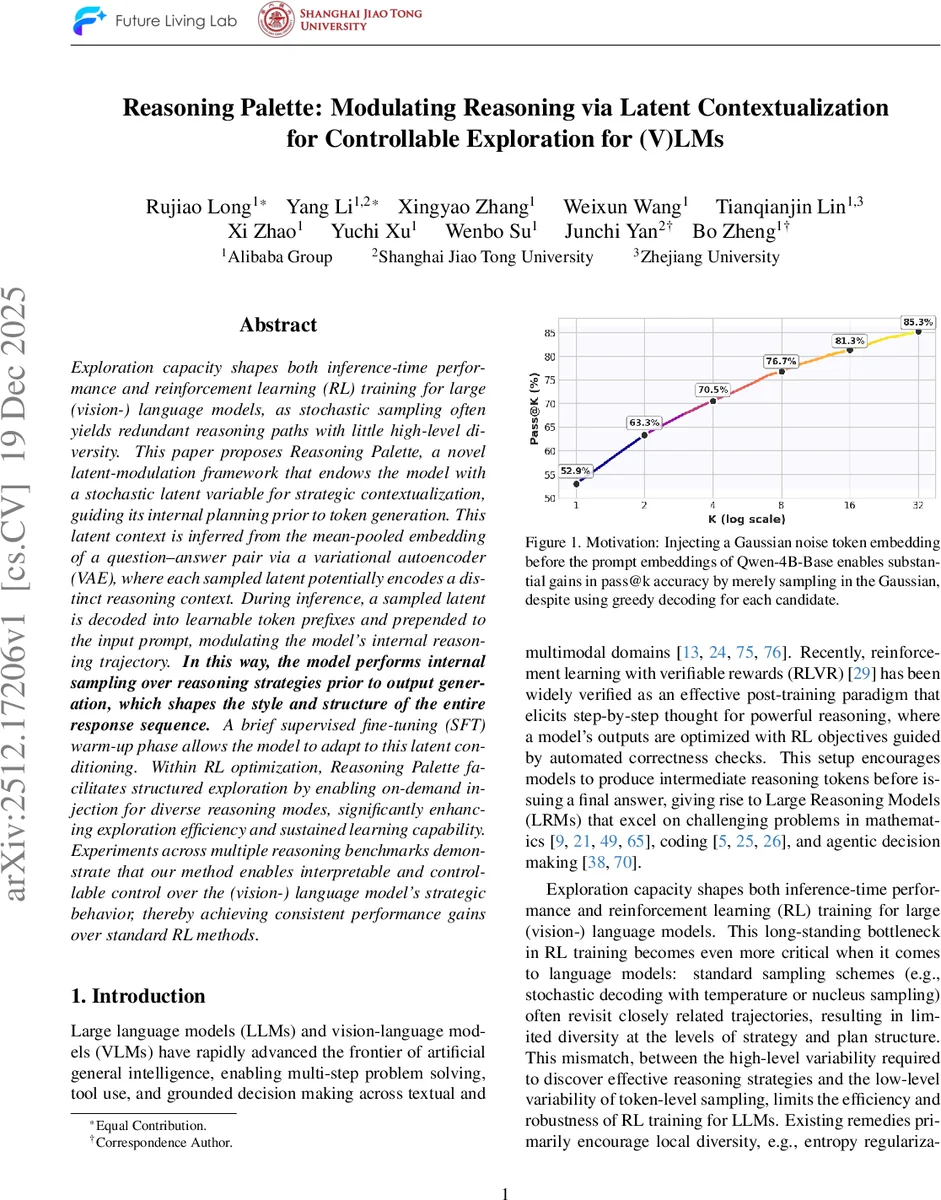
실험에서는 수학, 코드, 다중 홉 추론 등 다양한 베ン치마크에서 기존 PPO/GRPO 대비 Pass@k, 정확도, 다양성 지표가 모두 향상되었으며, 프리픽스 길이 L을 조절해 제어 강도를 미세하게 튜닝할 수 있음을 보였다. 특히, Figure 1에서 보여준 바와 같이 단순히 가우시안 노이즈 임베딩을 하나 삽입하는 것만으로도 Greedy 디코딩 상황에서 Pass@k가 크게 상승한다는 현상은, 모델 내부 플래닝 단계가 토큰 수준보다 훨씬 높은 차원에서 조정될 수 있음을 강력히 시사한다.
요약하면, Reasoning Palette는 (1) VAE 기반 잠재 공간을 통해 고수준 추론 전략을 확률적으로 샘플링, (2) 연속 프리픽스 삽입으로 기존 모델 구조를 그대로 활용, (3) 짧은 SFT로 프리픽스에 대한 적응을 촉진, (4) RL 훈련 시 전략적 탐색을 구조화함으로써, 대형 언어·비전 모델의 탐색 효율과 제어 가능성을 동시에 향상시키는 혁신적 프레임워크라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기