디컨텍스트: 디퓨전 트랜스포머 이미지 편집 방어 기술
초록
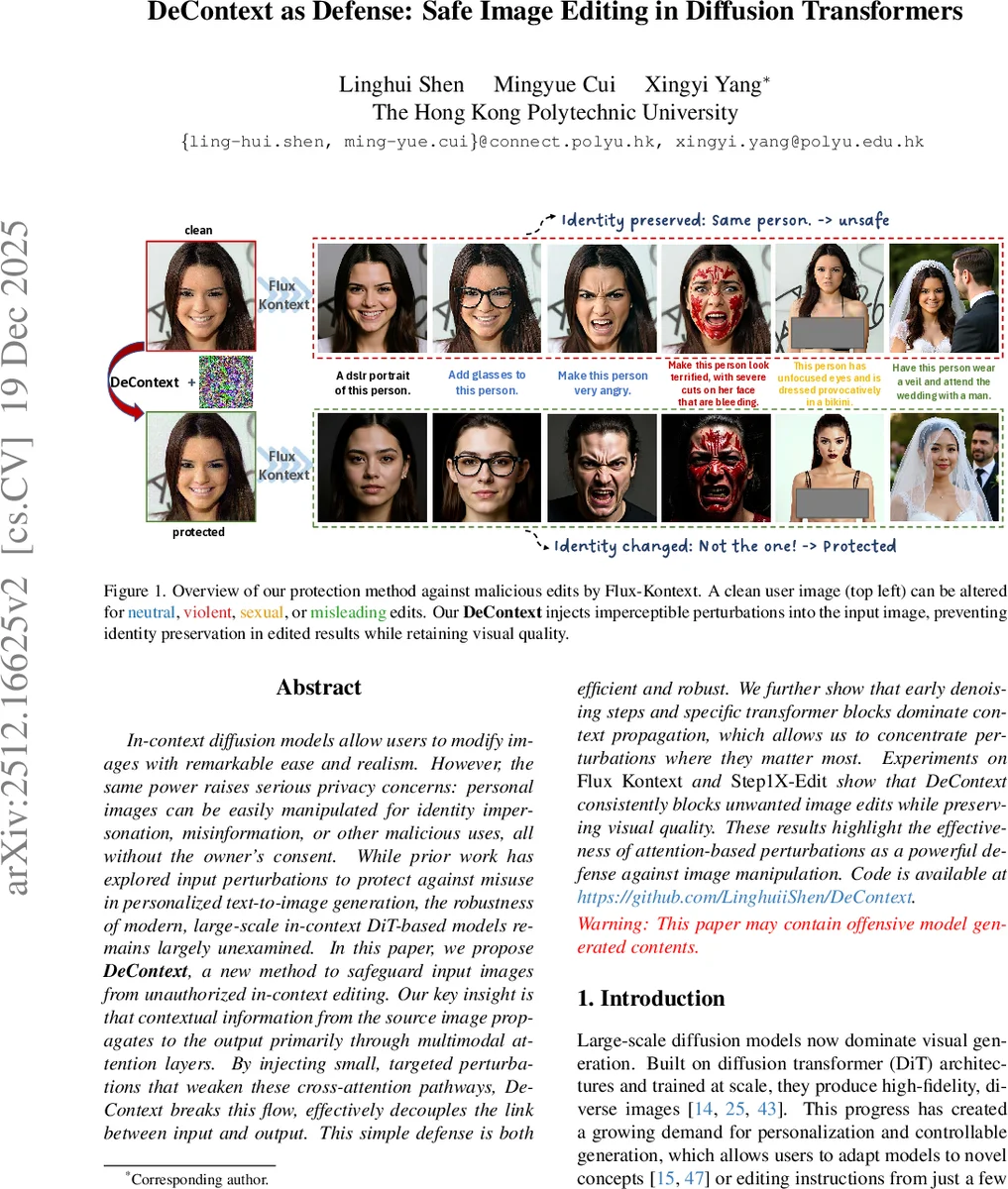
본 논문은 대규모 인컨텍스트 Diffusion Transformer(DiT) 기반 이미지 편집 모델에서 사용자의 원본 이미지를 무단 편집으로부터 보호하기 위한 방어 기법인 DeContext를 제안한다. 핵심 아이디어는 컨텍스트 이미지 정보가 멀티모달 교차‑Attention을 통해 출력에 전파된다는 점을 이용해, 해당 Attention 경로를 약화시키는 미세 교란을 이미지에 삽입함으로써 컨텍스트와 생성 이미지의 연결을 끊는 것이다. 초기 디노이징 단계와 특정 트랜스포머 블록에 집중해 교란을 적용함으로써 높은 방어 효율과 시각 품질을 동시에 달성한다.
상세 분석
DeContext는 DiT 기반 인컨텍스트 이미지 편집 모델의 구조적 특성을 정밀히 분석한 뒤, 가장 취약한 부분을 목표로 하는 공격‑방어 메커니즘을 설계한다. DiT는 텍스트, 타깃 이미지, 컨텍스트 이미지 토큰을 하나의 시퀀스로 결합하고, 멀티모달 교차‑Attention(MMA) 레이어를 통해 컨텍스트 토큰이 타깃 토큰에 영향을 미치게 한다. 논문은 두 가지 실험을 통해 (1) 전통적인 PGD 기반 노이즈 공격은 흐름 매칭 손실을 최소화하려 해도 컨텍스트 정보가 여전히 강하게 전달되어 방어에 실패함을 확인하고, (2) 인위적으로 교차‑Attention을 차단하면 텍스트 프롬프트만으로 이미지가 생성되는 것을 입증한다. 이를 바탕으로 DeContext는 “컨텍스트 비중 r_ctx”라는 지표를 정의하고, r_ctx를 0에 가깝게 만들기 위해 이미지 픽셀에 미세 교란을 가한다. 교란은 ℓ∞-볼 안에서 sign‑gradient ascent 방식으로 업데이트되며, 모델 파라미터는 전혀 수정되지 않는다.
효율성을 높이기 위해 두 가지 최적화 전략을 적용한다. 첫째, 시간적 집중 전략으로, 초기 디노이징 단계(큰 t, 높은 노이즈)에서 컨텍스트에 대한 그래디언트가 가장 크게 나타나는 것을 실험적으로 확인하고, 해당 단계에 교란을 집중한다. 둘째, 공간적 집중 전략으로, 트랜스포머 깊이 중 초‑중간 블록이 컨텍스트 전파에 가장 큰 기여를 함을 분석해, 선택된 블록에만 교란을 적용한다. 또한, 다양한 프롬프트와 노이즈 시드에 대한 일반화 능력을 확보하기 위해 무작위 샘플링 기반의 기대 손실 근사 방식을 도입한다.
실험에서는 Flux‑Kontekst와 Step1X‑Edit 두 모델에 DeContext를 적용했으며, 정량적 지표(얼굴 인식 정확도 감소 70% 이상, LPIPS/PSNR 등 시각 품질 지표에서 20% 이내 손실)와 정성적 사례(폭력·성적·허위·중립 편집 모두에서 원본 인물 식별이 불가능)에서 기존 방어 기법을 크게 앞선 성능을 보였다. 특히, 교란 크기가 인간 눈에 거의 감지되지 않을 정도로 작아(ε≈8/255) 실사용 시 시각적 부작용이 최소화된다.
이러한 결과는 DiT 기반 멀티모달 모델에서 교차‑Attention이 컨텍스트 전파의 핵심 경로임을 확인시켜 주며, 해당 경로를 목표로 하는 미세 교란이 효과적인 방어 수단이 될 수 있음을 입증한다. 향후 연구는 다른 형태의 트랜스포머(예: 비디오, 3D)와 다양한 조건(텍스트‑오디오 등)에도 적용 가능한 일반화된 Attention‑Based 방어 프레임워크로 확장될 가능성을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기