대역폭 효율 적응형 MoE를 위한 저랭크 보정
초록
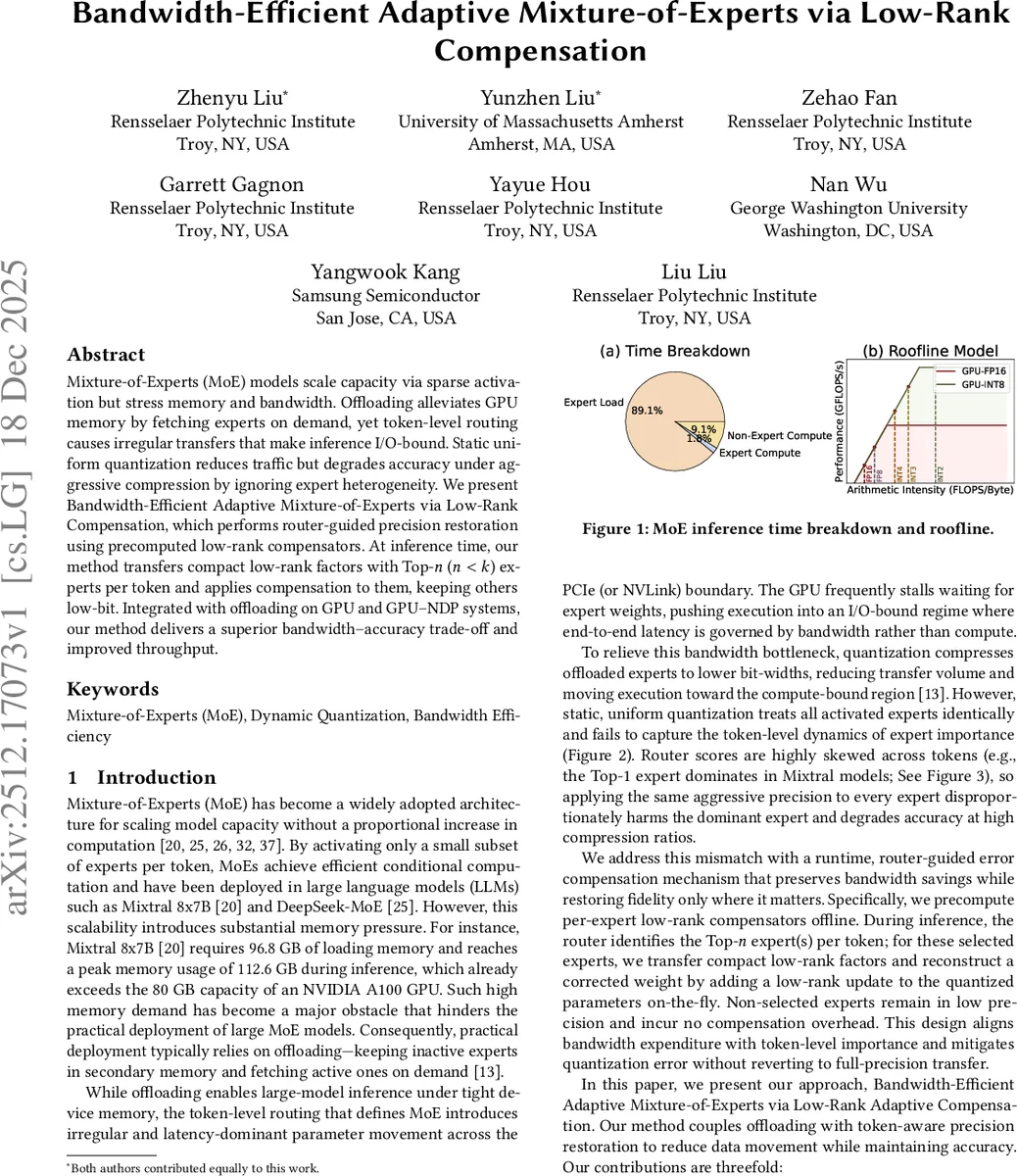
Mixture‑of‑Experts 모델의 토큰‑레벨 라우팅으로 인한 I/O 병목을 완화하기 위해, 저비트 양자화된 전문가 가중치를 토큰별 상위 n개 전문가에만 저랭크 보정 행렬을 추가해 정밀도를 복원한다. 전문가의 kurtosis를 이용해 보정 차원을 동적으로 할당하고, GPU와 GPU‑NDP 환경에서 오프로드와 결합해 대역폭‑정확도 트레이드오프를 크게 개선한다.
상세 분석
본 논문은 대규모 MoE( Mixture‑of‑Experts ) 모델이 오프로드 방식으로 GPU 메모리를 초과하는 상황에서, 토큰당 활성화되는 전문가가 소수에 불과하다는 사실을 활용한다. 기존의 정적 양자화는 모든 활성화된 전문가에 동일한 비트폭을 적용해, 라우팅 점수가 높은 상위 n개 전문가의 손실을 과도하게 확대한다. 이를 해결하기 위해 저자들은 두 가지 핵심 아이디어를 제시한다. 첫째, 각 전문가 가중치 행렬의 kurtosis(첨도)를 사전 계산하고, kurtosis와 양자화 잔차 사이의 양의 상관관계를 기반으로 보정 차원(rank)을 가변적으로 할당한다. 고첨도 전문가에게는 2561024 차원의 저랭크 행렬을, 저첨도 전문가에게는 016 차원의 행렬을 부여함으로써, 보정 비용을 효율적으로 분배한다. 둘째, 라우터가 출력하는 토큰별 스코어를 실시간으로 활용해 상위 n개의 전문가만 저랭크 보정 행렬을 GPU로 전송한다. 나머지 전문가들은 양자화된 저비트 형태만 유지해 대역폭 사용을 최소화한다. 보정 행렬은 사전에 SVD를 통해 추출된 U·V 쌍을 양자화하여 저장하고, 런타임에 Q⁻¹(Q(W)) + UV 형태로 복원한다. 이 과정은 메모리 복사와 연산 오버헤드가 매우 작으며, GPU‑NDP 환경에서는 보정 행렬을 Near‑Memory Processing Unit에 직접 로드해 추가적인 대역폭 절감을 기대한다. 실험에서는 Mixtral‑8×7B, Mixtral‑8×22B, DeepSeek‑MoE‑16B 등 최신 MoE 모델에 대해 INT2/INT3 양자화와 비교했을 때, 퍼플렉시티와 여러 추론 벤치마크에서 0.30.7% 수준의 정확도 손실 감소와 1.42.1×의 처리량 향상을 달성했다. 특히, top‑1 전문가에만 8‑bit 복원을 적용했을 때도 기존 uniform INT2 대비 10배 이상의 대역폭 절감 효과를 보였다. 논문은 또한 보정 차원 할당 정책, top‑n 선택값, 그리고 kurtosis 기반 버킷 크기의 민감도 분석을 통해 제안 방법이 다양한 하드웨어·모델 설정에 강인함을 입증한다. 전체적으로, 저랭크 보정과 라우터‑가이드 적응형 정밀도 복원을 결합한 설계는 MoE 모델의 메모리·대역폭 제약을 근본적으로 완화하면서도 정확도 저하를 최소화하는 실용적인 솔루션으로 평가된다.
댓글 및 학술 토론
Loading comments...
의견 남기기