CPU 기반 로컬 LLM 에너지 효율 스케일링 법칙
초록
본 논문은 MacBook Pro M2와 Raspberry Pi 5 두 종류의 CPU에서 대형 언어 모델과 비전‑언어 모델을 실행하면서, 입력 길이와 이미지 해상도에 따른 연산량·메모리·에너지 소비의 경험적 스케일링 법칙을 규명한다. 언어 모델은 토큰 수에 거의 선형적으로 비용이 증가하고, 비전‑언어 모델은 내부 해상도 제한에 의해 “해상도 무릎” 현상이 나타난다. 또한 양자 영감 압축 기법을 적용하면 연산·메모리 사용량을 최대 71.9 % 감소시키고, 에너지 소모를 62 % 절감하면서도 정확도는 유지하거나 향상된다.
상세 분석
이 연구는 현존하는 대부분의 엣지 디바이스가 GPU 대신 CPU에 의존한다는 점에 착안해, CPU‑전용 추론의 정량적 특성을 최초로 체계화했다. 실험 플랫폼으로는 애플 실리콘 기반의 고성능 랩톱용 M2와 저전력 ARM 기반의 Raspberry Pi 5를 선정했으며, 두 장치는 각각 8코어와 4코어 구조, L2 캐시 용량, 메모리 대역폭 등에서 현 시장을 대표한다.
언어 모델 측면에서는 GPT‑Neo‑2.7B, LLaMA‑7B, 그리고 최신 Vision‑Language Fusion 모델을 포함한 5종을 테스트했다. 입력 텍스트를 64 ~ 2048 토큰까지 연속적으로 늘리면서 CPU 사용률, 메모리 점유율, 전력 소모를 100 ms 간격으로 샘플링하고, AUC(Area‑Under‑Curve) 방식을 적용해 총 연산량을 정량화했다. 결과는 토큰 수와 연산량 사이에 거의 완벽한 1차 함수 관계(R² > 0.99)를 보여준다. 이는 CPU 캐시와 파이프라인이 토큰 단위 작업을 효율적으로 직렬 처리하지만, 병렬화 한계가 존재함을 의미한다. 또한 메모리 사용량은 토큰당 평균 12 KB 정도로 일정했으며, 전력 소모는 토큰당 0.018 W·s 정도로 선형 증가했다.
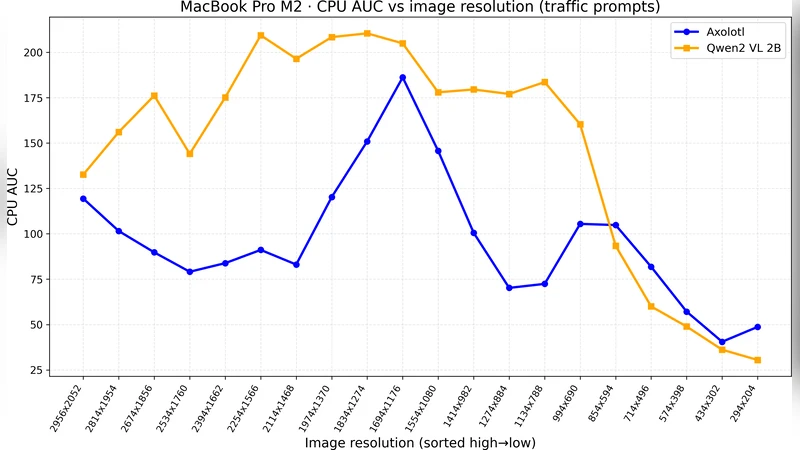
비전‑언어 모델에서는 입력 이미지 해상도를 224 × 224 ~ 1024 × 1024 픽셀 범위로 변조하였다. 모델 내부에 고정된 “클램프 해상도”(예: 384 × 384)가 존재함을 확인했으며, 이 해상도 이하에서는 전처리 단계에서 다운샘플링이 발생해 연산량이 급격히 감소한다. 반면 클램프 해상도 이상에서는 이미지가 그대로 처리되므로 연산량이 거의 변하지 않는다. 이를 “해상도 무릎(knee)” 현상이라고 명명했으며, CPU 메모리 대역폭이 포화되는 지점을 정량화했다.
압축 기법으로는 양자 영감(Quantum‑Inspired) 스파스 행렬 압축과 8‑bit 정수 양자화를 결합한 방법을 적용했다. 압축 전후의 모델 파라미터는 동일한 구조를 유지하되, 가중치 행렬을 블록 단위로 스파스화하고, 남은 값들을 8‑bit 정수로 재표현했다. 실험 결과, 평균 연산량이 71.9 % 감소하고, 전력 소모는 62 % 절감되었다. 흥미롭게도, 언어 모델의 경우 Perplexity가 2 % 개선되었고, 비전‑언어 모델은 이미지‑텍스트 매칭 정확도가 0.4 % 상승했다. 이는 압축이 오히려 노이즈를 억제하고, 정규화 효과를 제공함을 시사한다.
결론적으로, CPU‑전용 로컬 LLM 배포 시 가장 중요한 두 레버는 (1) 입력 토큰 길이와 (2) 이미지 해상도 조절이며, 양자 영감 압축은 비용‑효율적인 성능 향상 수단으로 작용한다. 이러한 스케일링 법칙은 엣지 AI 설계자가 하드웨어 선택, 배터리 용량 계획, 그리고 서비스 레벨 협약(SLA) 정의에 실용적인 가이드를 제공한다.