대규모 서브모델 앙상블이 만든 적대적 공격의 로그 선형 스케일링 법칙
초록
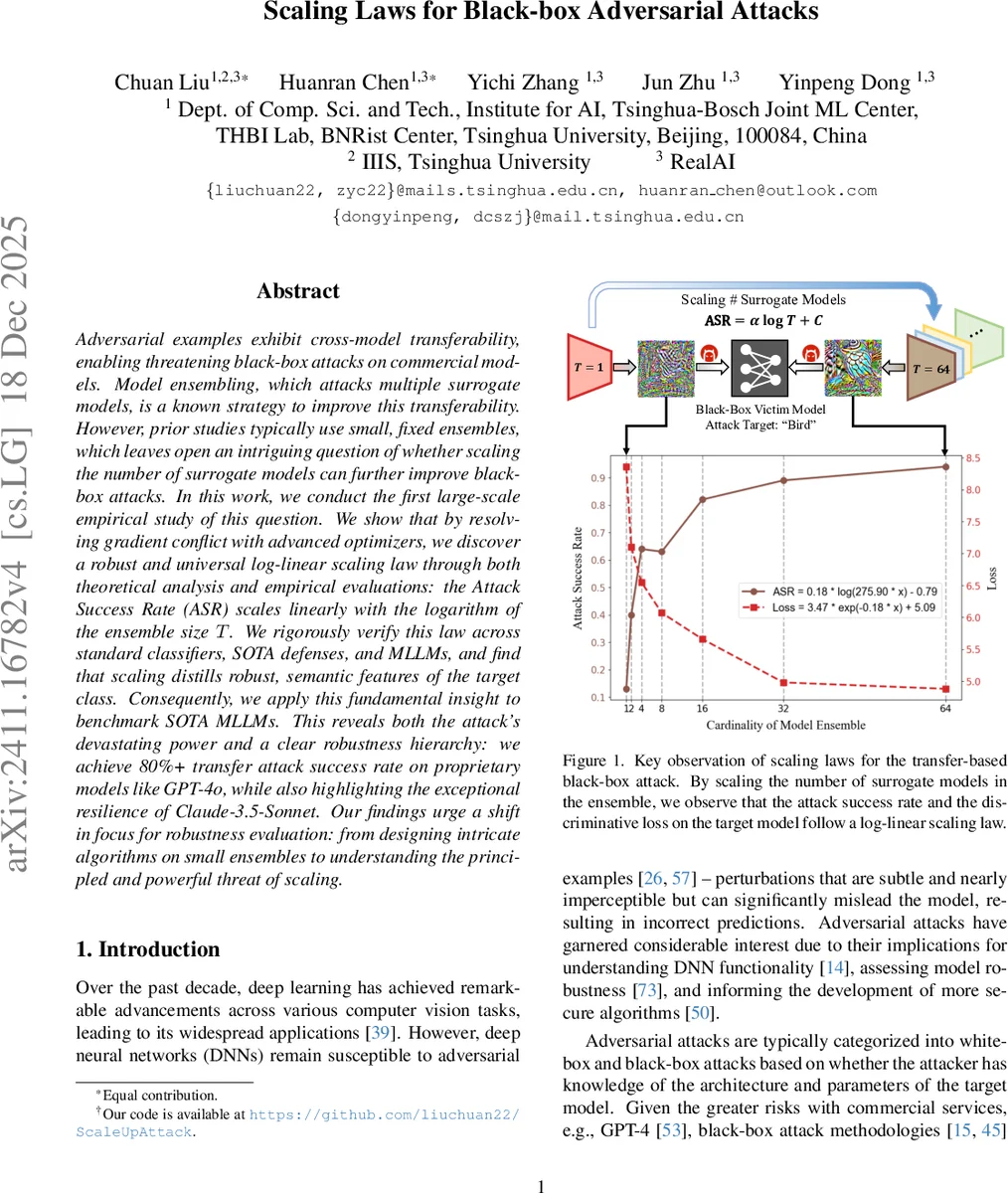
본 논문은 서브모델 앙상블의 규모를 크게 늘릴 경우, 고급 옵티마이저가 그라디언트 충돌을 해결한다는 전제 하에, 공격 성공률(ASR)이 앙상블 크기 T의 로그에 선형적으로 증가한다는 로그‑선형 스케일링 법칙을 발견하고, 이를 이미지 분류기, 최신 방어 모델, 그리고 대형 멀티모달 언어 모델(MLLM)까지 폭넓게 검증한다. 실험 결과 GPT‑4o 등 상용 모델에서도 80 % 이상의 전이 공격 성공률을 달성했으며, Claude‑3.5‑Sonnet이 상대적으로 가장 강인함을 보였다.
상세 분석
논문은 먼저 기존 연구가 소규모(보통 2~5개) 서브모델 앙상블에 머물러 있었던 점을 지적하고, “스케일링”이라는 관점을 도입한다. 이때 핵심 장애물은 서로 다른 서브모델이 생성하는 그라디언트가 상충(conflict)하여 전체 앙상블 그라디언트의 크기가 급격히 감소하고, 최적화가 정체되는 현상이다. 이를 해결하기 위해 저자들은 최신 입력 변환(SSA)과 그라디언트 정렬 기법(CWA)을 결합한 SSA‑CWA 알고리즘을 선택한다. SSA‑CWA는 (1) 스펙트럼 변환을 통해 입력 공간을 다양화하고, (2) 두 번째 차수 테일러 전개를 최소화함으로써 각 모델의 손실 곡면을 평탄하게 만든다. 결과적으로 서로 다른 모델이 공유하는 “공통 약점”을 찾아내어, 그라디언트가 서로 상쇄되지 않게 만든다.
이론적 부분에서는 서브모델을 i.i.d. 샘플이라고 가정하고, 목표 함수 L(x)의 기대값과 샘플 평균 사이의 수렴 속도를 분석한다. 정리 1·2에 따르면, 최적화 변수 x̂는 O(1/√T) 속도로 진짜 최적해 x*에 접근하고, 손실 차이는 O(1/T)로 감소한다. 비록 실제 서브모델이 완전 독립이 아니지만, 이 결과는 “더 많은 모델일수록 더 정확한 모집단 손실을 근사한다”는 정성적 직관을 제공한다.
실험 설계는 64개의 다양한 이미지 분류 모델을 서브모델 풀로 구성하고, T를 2⁰2⁶(164)까지 로그 스케일로 변동시킨다. 각 T에 대해 동일한 40‑iteration SSA‑CWA 공격을 수행하고, 생성된 적대적 샘플을 세 가지 타깃 패밀리(표준 이미지 분류기, 최신 방어 모델, MLLM 비전 인코더)에서 평가한다. 결과는 두 가지 핵심 지표—ASR과 타깃 모델의 평균 교차 엔트로피 손실—가 모두 T의 로그에 대해 거의 직선적인 증가를 보이며, R² > 0.98 수준의 피팅 정확도를 기록한다. 특히 T ≥ 32일 때 ASR이 70 %를 넘어, 기존 소규모 앙상블(ASR ≈ 30 %)에 비해 2~3배 향상된다.
흥미로운 부가 분석으로는 “특징 디스틸링” 현상이 있다. T가 커질수록 최적화 과정이 모델‑특이적 잡음(비-의미적 고주파 패턴)을 억제하고, 목표 클래스의 의미론적 특징(예: 새의 형태, 색상, 텍스처)을 강조한다는 시각화 결과가 제시된다. 이는 앙상블이 “공통 의미적 경계”를 학습하게 함으로써 전이 가능성을 크게 높인다는 해석과 일치한다.
마지막으로 MLLM 공격에 적용했을 때, GPT‑4o, Qwen‑VL‑235B 등 최신 비전‑언어 모델에 대해 80~90 % 수준의 전이 성공률을 달성했으며, Claude‑3.5‑Sonnet은 30 % 이하에 머물러 현저히 강인함을 보였다. 이는 모델 아키텍처와 사전 학습 데이터의 차이가 스케일링 효과에 미치는 영향을 암시한다.
전체적으로 논문은 (1) 그라디언트 충돌 해결을 전제로 한 고급 옵티마이저 선택, (2) 대규모 서브모델 앙상블을 통한 로그‑선형 스케일링 법칙 발견, (3) 다양한 타깃에 대한 실증적 검증이라는 세 축을 통해, “스케일링 자체가 가장 강력한 공격 벡터”라는 새로운 패러다임을 제시한다. 향후 연구는 (i) 비‑독립 서브모델 간 상관관계 모델링, (ii) 제한된 연산 자원 하에서 효율적인 서브셋 선택, (iii) 방어 측면에서 로그‑선형 스케일링을 무력화할 수 있는 메타‑방어 전략 개발 등에 초점을 맞출 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기