단일 이미지 모델의 한계를 넘어, 다중 뷰 일관성으로 3D 인식력을 높이다
초록
단일 이미지 기반의 파운데이션 모델(DINO, CLIP 등)은 다중 뷰 이미지를 독립적으로 처리해 동일 3D 점의 특징이 일관되지 않는 문제가 있습니다. 본 연구는 추론 단계에서 작동하는 ‘다중 뷰 어댑터’를 도입해, 카메라 포즈 정보를 활용하여 여러 뷰의 특징을 기하학적으로 일관되게 정렬하는 방법을 제안합니다. 이를 통해 별도의 3D 모델 재구성 없이도 정확한 대응점 추정 및 3D 인식 작업 성능을 크게 향상시킵니다.
상세 분석
본 논문의 핵심 기술적 기여는 사전 학습된 2D 파운데이션 모델의 강력한 의미론적 사전 지식을 유지하면서, 효율적으로 3D 기하학적 일관성을 주입하는 ‘다중 뷰 어댑터(MV-Adapter)’ 프레임워크에 있습니다. 기존 3D 일관성 방법들이 네안더(NeRF)나 가우시안 스플래팅(Gaussian Splatting) 기반의 장면별 최적화에 의존하거나(FiT3D는 단일 이미지 추론에 의존), 계산 비용이 높은 문제를 가지고 있었던 반면, 본 방법은 추론 시 여러 뷰를 한 번의 순전파로 처리하여 실용성을 높였습니다.
구체적으로, 트랜스포머 블록 사이에 삽입되는 어댑터는 플뤼커(Plücker) 임베딩으로 표현된 카메라 레이 정보를 조건으로 받아, 다른 뷰의 특징과 3D 인식 어텐션을 수행합니다. 어댑터는 제로-합성곱(Zero-Conv)으로 초기화되어 사전 학습 모델의 동작을 초기에는 보존하며, LoRA 기반의 파라미터 효율적 미세 조정과 결합되어 학습됩니다.
손실 함수 설계에서도 중요한 통찰이 적용되었습니다. 단순히 대응점 특징 간 L2 거리를 최소화하면 특징 붕괴(feature collapse)가 일어날 수 있으므로, 저자들은 기하학 인식 밀집 손실(geometry-aware dense loss)을 채택했습니다. 이는 한 뷰의 질의 특징과 다른 뷰의 모든 위치 간 유사도 맵을 생성한 후, 소프트맥스와 SoftArgMax를 통해 예측 대응점을 구하고, 실제 대응점과의 오차를 최소화합니다. 이는 특징 자체가 아닌, 특징이 생성하는 기하학적 매핑의 정확성을 학습 대상으로 삼아 트리비얼 솔루션을 회피합니다. 또한 원본 특징 공간과의 코사인 유사도 및 노름(norm)을 유지하는 정규화 항을 추가하여 의미론적 정보의 이탈을 방지합니다.
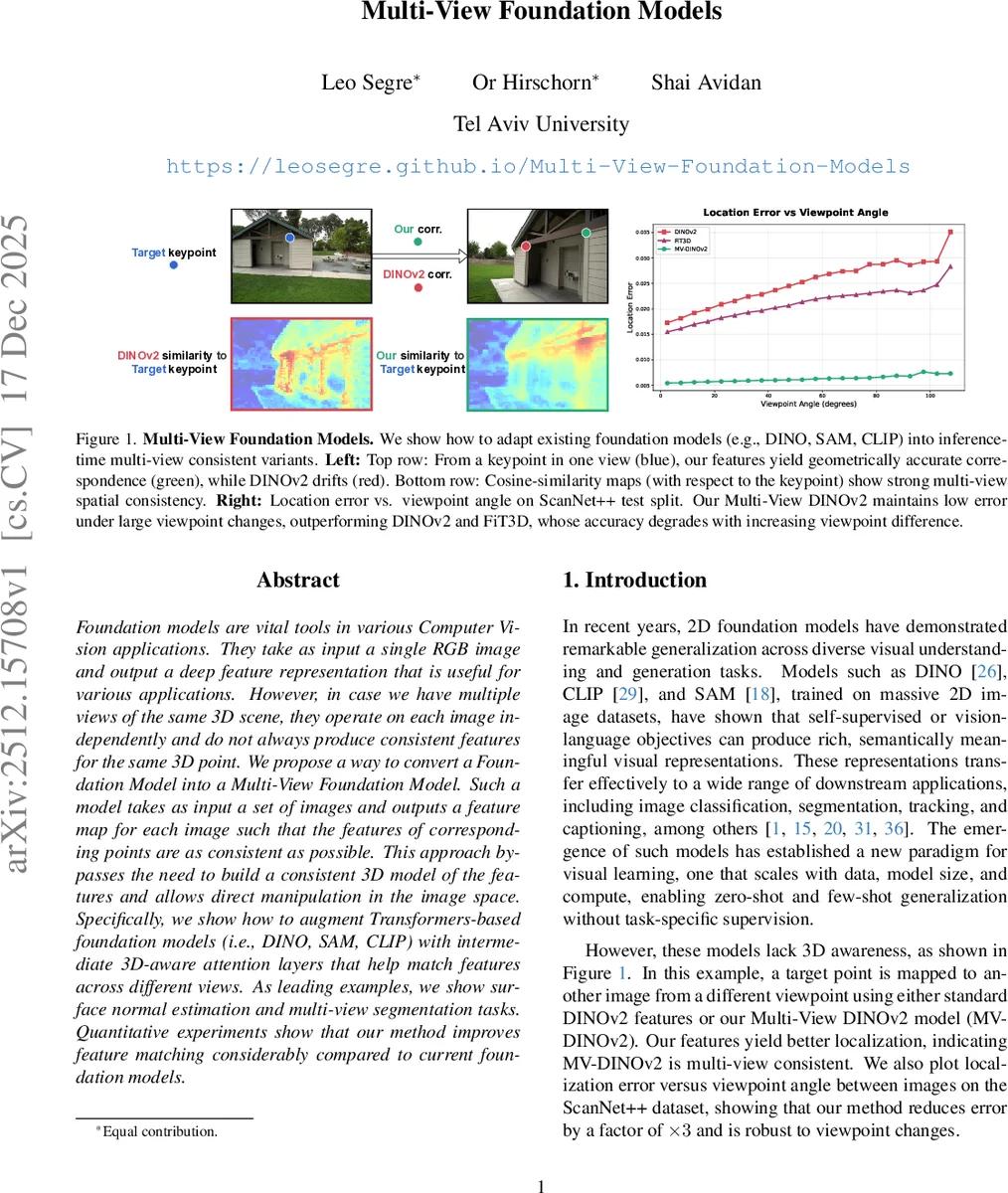
실험 결과(표1, 그림1)는 이 방법론의 효과를 입증합니다. DINOv2, CLIP 등 다양한 백본에서 ScanNet++ 및 일반화 벤치마크에서 기준 모델(Base)이나 FiT3D 대비 대응점 위치 오차(Loc. Err.)를 크게 감소시켰으며(예: DINOv2 기준 0.1029 → 0.0247), 원본 특징과의 유사도(Base Sim.)도 높게 유지했습니다(0.9376). 이는 순수 3D 일관성만이 아닌 ‘의미론-기하학 균형’을 잘 달성했음을 보여줍니다. 또한 표면 법선 추정, 다중 뷰 분할과 같은 다운스트림 3D 작업에서의 유용성도 확인되었습니다.
댓글 및 학술 토론
Loading comments...
의견 남기기