프롬프트 반복으로 비추론 LLM 성능 급상승
초록
본 논문은 추론을 사용하지 않을 때 입력 프롬프트를 두 번 연속으로 제공하면 Gemini, GPT‑4o‑mini, Claude, DeepSeek 등 주요 대형 언어 모델의 정확도가 크게 향상된다는 사실을 실험적으로 입증한다. 반복은 생성 토큰 수나 응답 지연시간을 증가시키지 않으며, 사전‑채우기 단계에서만 추가 연산이 발생한다. 다양한 벤치마크와 커스텀 테스트에서 70개 실험 중 47건에서 통계적으로 유의미한 개선을 보였으며, 이유는 토큰 간 상호주의(attention)가 강화돼 프롬프트 정보를 더 완전하게 활용할 수 있기 때문이다.
상세 분석
이 연구는 인과적(causal) 언어 모델이 과거 토큰만을 참조하도록 설계된 점에 착안한다. 기존 단일 프롬프트에서는 앞에 위치한 토큰이 뒤에 있는 토큰을 보지 못해, “문맥‑질문” 순서와 “질문‑문맥” 순서 사이에 성능 차이가 발생한다는 점을 확인한다. 프롬프트를 그대로 복제해 “
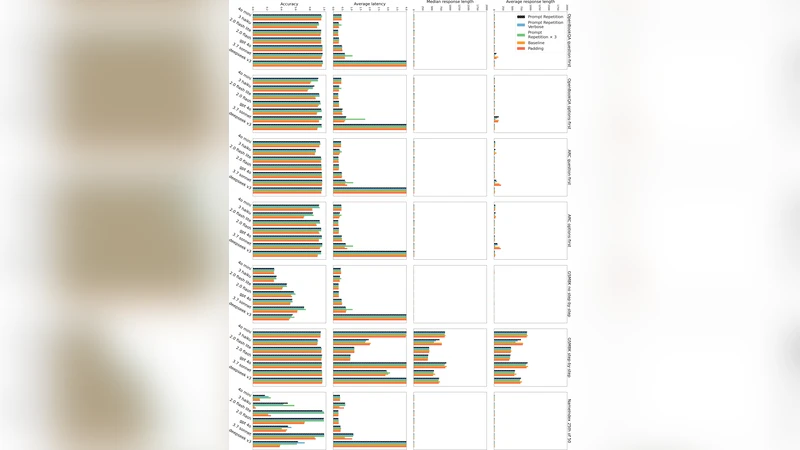
실험에서는 Gemini 2.0 Flash/Flash Lite, GPT‑4o‑mini/4o, Claude 3 Haiku/7 Sonnet, DeepSeek V3 등 7개 모델을 7개 벤치마크(ARC‑Challenge, OpenBookQA, GSM8K, MMLU‑Pro, MA‑TH 등)와 두 개의 자체 제작 과제(NameIndex, MiddleMatch)에 적용했다. 추론 없이 단순 정확도를 측정했을 때, 프롬프트 반복은 47/70 조합에서 통계적으로 유의미한 승리를 기록했으며, 손실은 전혀 없었다. 특히 NameIndex와 MiddleMatch 같은 순서‑민감 과제에서는 정확도가 20%대에서 90%대 이상으로 급격히 상승했다.
다양한 변형도 검증했다. “Verbose” 버전은 프롬프트 앞에 “Let me repeat that:” 같은 문구를 삽입했으며, “×3” 버전은 세 번 반복했다. 두 변형 모두 기본 반복과 비슷하거나 더 좋은 성능을 보였으며, 특히 “×3”은 커스텀 과제에서 큰 이득을 제공했다. 반면 입력 길이만 늘리는 “Padding”(마침표 삽입) 방식은 성능 향상이 없었으며, 이는 단순 길이 증가가 아니라 토큰 간 상호작용 강화가 핵심임을 입증한다.
효율성 측면에서, 프롬프트 반복은 생성 단계의 토큰 수와 지연시간을 증가시키지 않았다. API 호출 시 측정된 평균·중위수 지연시간은 모든 모델에서 거의 동일했으며, 단지 사전‑채우기 단계에서 입력 토큰이 두 배가 되므로 약간의 전처리 비용만 발생한다. 다만 Claude Haiku와 Sonnet은 매우 긴 입력(특히 NameIndex·MiddleMatch)에서 KV‑cache 관리 비용으로 지연이 약간 늘었다.
이 논문은 기존 “Chain‑of‑Thought”나 “Think step‑by‑step”과 같은 추론 촉진 프롬프트와는 달리, 출력 길이를 늘리지 않으면서도 비추론 작업에서 즉각적인 성능 향상을 제공한다는 점에서 실용적이다. 그러나 몇 가지 한계도 존재한다. 첫째, 실험은 모두 공개 API를 통한 블랙박스 호출에 의존했으며, 내부 KV‑cache 활용 방식이나 모델 내부 구조에 대한 직접적인 분석은 부족하다. 둘째, 반복이 효과적인 정확한 토큰 수(2회가 최적인지, 3회 이상도 가능한지)와 긴 프롬프트(수천 토큰)에서의 적용 가능성은 추가 연구가 필요하다. 셋째, 현재는 텍스트 입력에만 초점을 맞추었으나, 멀티모달 모델이나 이미지‑텍스트 혼합 프롬프트에 대한 확장 가능성은 미검증이다.
향후 연구 방향으로는 (1) 반복된 프롬프트를 포함한 데이터셋으로 사전학습 혹은 파인튜닝을 진행해 모델이 구조적으로 반복을 활용하도록 하는 방법, (2) 생성 단계에서 KV‑cache에 두 번째 복제본만 남겨 완전한 지연 비용 제로화, (3) 부분 반복(핵심 문장만)이나 동적 순서 재배열을 통한 효율성 극대화, (4) 멀티턴 대화 시 반복이 어떻게 작용하는지 탐구, (5) 이미지·음성 등 비텍스트 모달리티에 대한 적용 가능성 검증 등이 제시된다. 전반적으로 프롬프트 반복은 간단하면서도 비용 효율적인 성능 향상 기법으로, 비추론 기반 애플리케이션에 즉시 적용할 수 있는 실용적 도구라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기