추천 시스템의 지능적 진화 RecGPT-V2 멀티 에이전트와 강화학습의 결합
초록
RecGPT-V2는 기존 LLM 기반 추천 시스템의 연산 비효율성, 설명의 단조로움, 평가의 한계를 극복하기 위해 계층적 멀티 에이전트 시스템, 메타 프erv-prompting, 제약 조건 강화학습 및 에이전트 기반 평가 체계를 도입하여 타오바오(Taobao) 실서비스에서 압도적인 성능 향상을 입증한 차세대 추천 프레임워크입니다.
상세 분석
RecGPT-V2 기술 보고서의 핵심은 단순한 모델 파라미터의 확장이 아닌, 추천 프로세스의 ‘구조적 재설계’를 통한 지능화와 효율화의 동시 달성입니다. 본 논문은 기존 RecGPT-V1이 가졌던 네 가지 치명적인 병목 현상을 정밀하게 타격합니다.
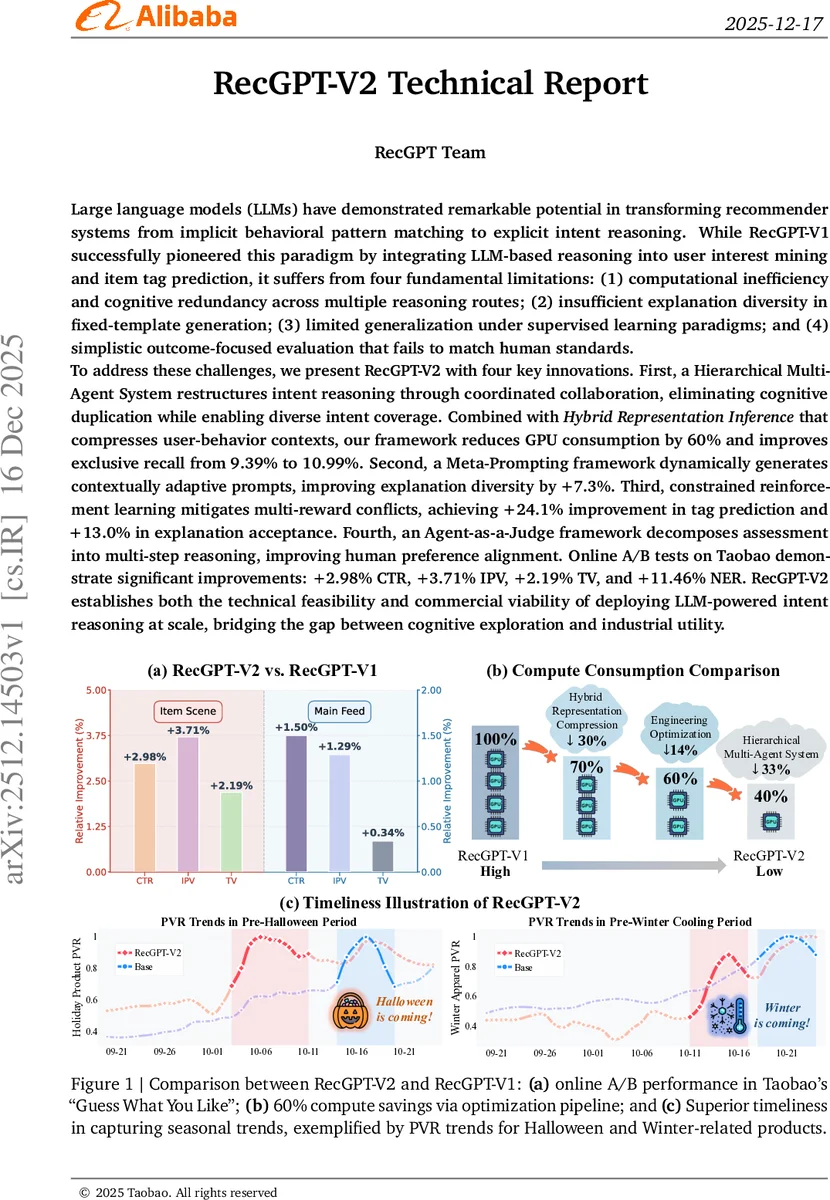
첫째, 연산 효율성 측면에서 ‘계층적 멀티 에이전트 시스템(Hierarchical Multi-Agent System)‘은 매우 혁신적입니다. 기존의 단일 경로 추론이 가졌던 인지적 중복을 에이전트 간의 협업 구조로 재편함으로써, 하이브리드 표현 추론(Hybrid Representation Inference)과 결합해 GPU 사용량을 60%나 절감했습니다. 이는 대규모 상용 서비스에서 LLM 도입의 가장 큰 걸림돌인 비용 문제를 해결할 수 있는 실질적인 돌파구입니다.
둘째, 추천의 질적 측면인 ‘설명의 다양성’을 메타 프롬프팅(Meta-Prompting)으로 해결했습니다. 고정된 템플릿은 사용자에게 지루함을 주지만, 문맥에 따라 동적으로 변하는 프롬프트는 설명의 다양성을 7.3% 향상시켰습니다.
셋째, 가장 기술적 난도가 높은 부분은 ‘제약 조건 강화학습(Constrained Reinforcement Learning)‘입니다. 추천 시스템에서는 정확도(Accuracy)와 다양성(Diversity), 그리고 설명의 수용성(Acceptance)이라는 상충하는 보상(Multi-reward) 간의 충돌이 발생합니다. RecGPT-V2는 이 충돌을 제약 조건 하의 최적화 문제로 정의하여, 태그 예측 정확도를 24.1%나 끌어올리는 성과를 거두었습니다.
마지막으로, ‘Agent-as-a-Judge’ 프레임워크는 평가의 패러다임을 바꿨습니다. 단순 수치 비교를 넘어, 에이전트가 다단계 추론을 통해 평가를 수행하게 함으로써 모델의 판단을 인간의 선호도와 정렬(Alignment)시켰습니다. 이는 추천 시스템이 단순한 패턴 매칭을 넘어, 인간과 유사한 논리적 판단 근거를 가질 수 있음을 시사합니다.
본 기술 보고서는 LLM(대규모 언어 모델)을 활용한 추천 시스템의 새로운 이정표를 제시하는 RecGPT-V2의 개발 과정과 성과를 다루고 있습니다. 기존의 추천 시스템이 사용자의 과거 행동 패턴을 매칭하는 ‘암묵적 패턴 매칭’에 머물렀다면, RecGPT-V2는 사용자의 의도를 논리적으로 추론하는 ‘명시적 의도 추론’ 시대를 열고자 합니다.
연구진은 선행 모델인 RecGPT-V1이 직면한 네 가지 핵심 한계를 식별했습니다. 첫째는 추론 경로의 중복으로 인한 연산 비효율성, 둘째는 고정된 템플릿 사용으로 인한 설명의 단조로움, 셋째는 지도 학습 기반 모델의 일반화 한계, 넷째는 인간의 복잡한 기준을 반영하지 못하는 단순한 평가 방식입니다.
이를 해결하기 위해 RecGPT-V2는 네 가지 핵심 혁신 기술을 도입했습니다.
- 계층적 멀티 에이전트 및 하이브리드 표현 추론: 에이전트 간의 유기적인 협업을 통해 중복된 추론 과정을 제거했습니다. 이를 통해 GPU 자원 소모를 60%나 줄이면서도, 사용자 행동 맥락을 압축하여 표현함으로써 독점적 리콜(Exclusive Recall) 성능을 9.39%에서 10.99%로 끌어올렸습니다.
- 메타 프롬프팅(Meta-Prompting) 프레임워크: 고정된 문구에서 벗어나, 현재의 문맥에 맞게 적응형 프롬프션을 생성합니다. 이는 추천 이유에 대한 설명의 다양성을 7.3% 증가시켜 사용자 경험을 풍부하게 만듭니다.
- 제약 조건 강화학습(Constrained Reinforcement Learning): 추천 시스템의 고질적 문제인 ‘다중 보상 간의 충돌’을 해결합니다. 정확도와 수용성 사이의 균형을 맞추기 위해 제약 조건을 설정한 강화학습을 적용하여, 태그 예측 성능을 24.1% 향상시키고 설명 수용성을 13.0% 높였습니다.
- Agent-as-a-Judge 프레임워크: 평가 프로세스 자체에 추론 능력을 부여했습니다. 에이전트가 다단계 추론을 통해 추천 결과의 적절성을 판단하게 함으로써, 모델의 출력값이 인간의 선호도와 일치하도록 정밀하게 조정했습니다.
이러한 기술적 진보는 실제 대규모 커머스 플랫폼인 타오바오(Taobao)의 A/B 테스트를 통해 그 상업적 가치가 입증되었습니다. 실험 결과, 클릭률(CTR)은 2.98%, 인당 상품 조회수(IPV)는 3.71%, 총 거래액(TV)은 2.19% 상승했으며, 특히 신규 상품 발견(NER) 지표는 11.46%라는 놀라운 상승폭을 기록했습니다. 결론적으로 RecGPT-V2는 LLM 기반의 의도 추론 기술이 단순한 연구 단계를 넘어, 대규모 산업 현장에서의 실질적인 운영과 수익 창출이 가능한 수준에 도달했음을 증명하고 있습니다.
댓글 및 학술 토론
Loading comments...
의견 남기기