실시간 비디오 인스턴스 분할을 위한 희소‑밀집 키마스크 증류
초록
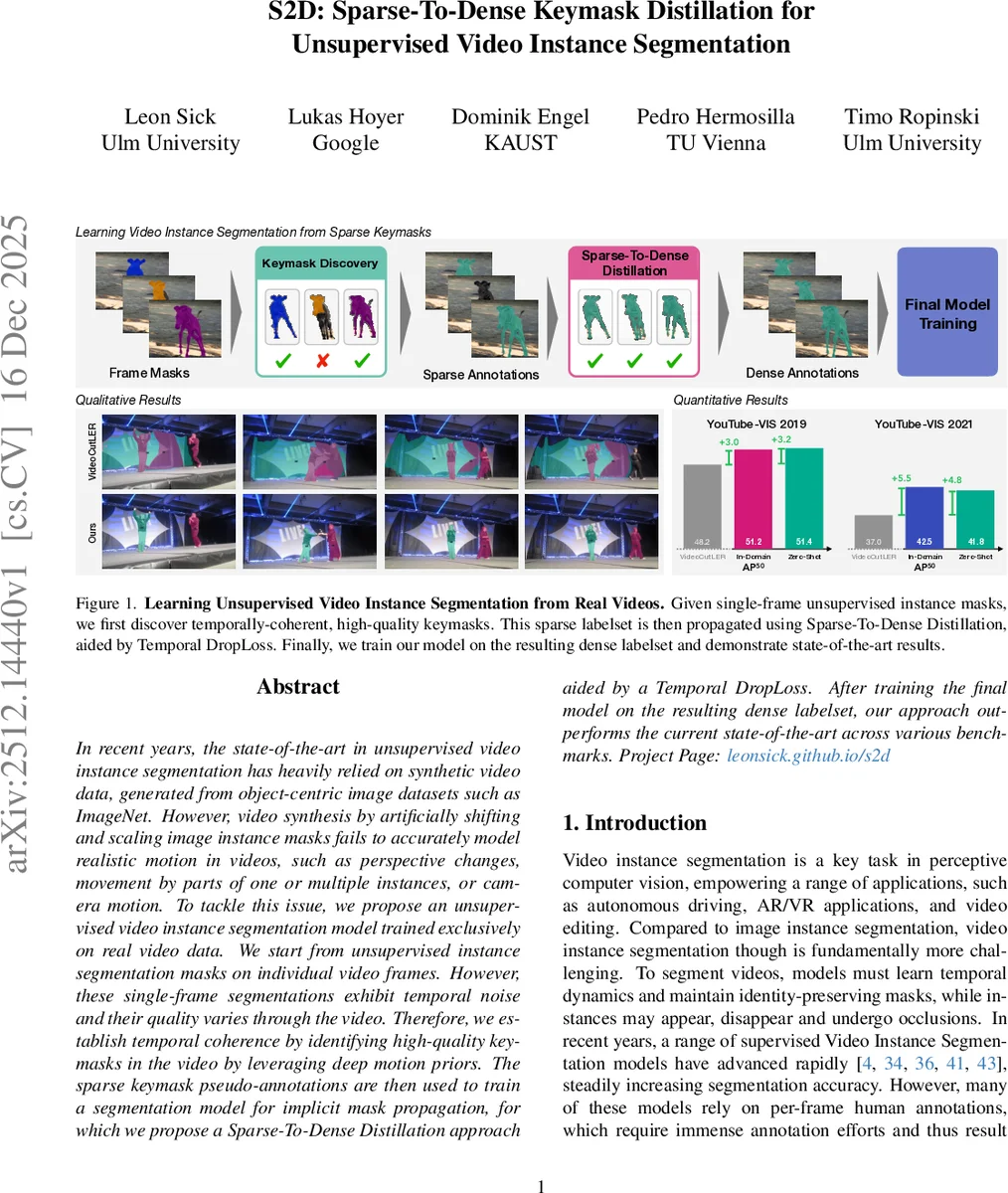
본 논문은 합성 영상이 아닌 실제 비디오만을 이용해 무감독 비디오 인스턴스 세그멘테이션을 학습한다. 단일 프레임에서 얻은 무감독 인스턴스 마스크를 깊은 모션 프라이어를 활용해 고품질 키마스크로 선별하고, 이를 ‘Sparse‑to‑Dense Distillation’과 ‘Temporal DropLoss’로 밀집 라벨로 확장한다. 최종 모델은 기존 합성 데이터 기반 방법들을 뛰어넘는 성능을 보이며, 인‑도메인 및 제로‑샷 평가 모두에서 최고 수준을 기록한다.
상세 분석
S2D는 크게 세 단계로 구성된다. 첫 번째 단계는 기존 무감독 이미지 인스턴스 세그멘테이션 모델(CutS3D 등)으로부터 프레임별 마스크를 추출하고, 포인트 트래커를 이용해 각 마스크에 대한 점 궤적을 생성한다. 이 궤적은 ‘가시성 벡터’를 만들고, DBSCAN 클러스터링을 통해 동일 시점에 동시에 나타나고 사라지는 마스크들을 ‘Visibility Group’으로 묶는다. 여기서 핵심은 가시성 일관성을 이용해 노이즈 마스크를 자동으로 걸러내는 것이다.
두 번째 단계인 ‘Proxy Propagate‑And‑Match’에서는 같은 Visibility Group 내에서 점 궤적을 실제 프레임 마스크에 투사한다. 투사된 점 집합과 목표 프레임 마스크 사이의 Point‑Mask Jaccard 지수를 계산해 매칭을 판단한다(λ_J=0). 매칭 행렬을 다시 DBSCAN에 넣어 세부 클러스터를 형성함으로써, 동일 가시성 구간을 공유하지만 서로 다른 객체(예: 사람과 차량)를 구분한다. 이 과정을 통해 얻어진 고품질 마스크를 ‘키마스크’라 부르며, 전체 비디오에서 매우 드문(희소)하지만 정확한 라벨 집합을 만든다.
세 번째 단계는 이러한 희소 라벨을 이용해 비디오 마스크 전파 모델(VideoMask2Former)을 학습하는데, 여기서 새롭게 제안된 ‘Temporal DropLoss’가 핵심 역할을 한다. 기존 손실은 모든 프레임에 라벨이 존재한다고 가정하지만, S2D는 라벨이 없는 프레임이 다수이다. Temporal DropLoss는 라벨이 없는 프레임에 대한 손실을 의도적으로 ‘드롭’시켜, 모델이 라벨이 있는 프레임에 집중하도록 유도한다. 동시에 ‘Sparse‑to‑Dense Distillation’에서는 키마스크를 Teacher 모델로, 동일 구조의 Student 모델을 학습시켜 라벨이 없는 프레임에서도 높은 품질의 마스크를 예측하도록 만든다. 두 단계(Teacher → Student)로 이루어진 이 증류 과정은 라벨이 희소한 상황에서도 시공간 일관성을 학습하게 하며, 최종적으로 전체 프레임에 대한 밀집 라벨을 생성한다.
S2D의 장점은 (1) 합성 데이터에 의존하지 않고 실제 비디오만으로 학습한다는 점, (2) 모션 프라이어와 점 트래킹을 활용해 자동으로 고품질 라벨을 추출함으로써 라벨링 비용을 완전히 제거한다는 점, (3) Temporal DropLoss와 증류 메커니즘을 통해 희소 라벨을 효과적으로 밀집 라벨로 변환한다는 점이다. 실험 결과, YouTube‑VIS 2019/2021 등 주요 벤치마크에서 AP50 기준 51.2~51.4%를 달성해 기존 VideoCutLER(≈48%)를 크게 앞선다. 또한, 인‑도메인 데이터뿐 아니라 외부 비디오 데이터로 확장했을 때 제로‑샷 성능이 크게 향상되는 것을 확인하였다.
한계점으로는 (a) 포인트 트래커와 DBSCAN 클러스터링에 의존하기 때문에 매우 빠른 움직임이나 급격한 시점 변화가 있는 영상에서는 키마스크 추출이 어려울 수 있다, (b) 현재는 단일 객체에 대한 마스크 품질을 기준으로 λ_J=0을 사용했지만, 복잡한 장면에서는 더 정교한 매칭 기준이 필요할 가능성이 있다. 향후 연구에서는 학습형 트래커와 적응형 매칭 스코어를 도입해 이러한 약점을 보완할 수 있을 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기