이미지 기억 탐지를 위한 통합 모델 LCMem: 강건한 재식별·복제 검출의 새로운 기준
초록
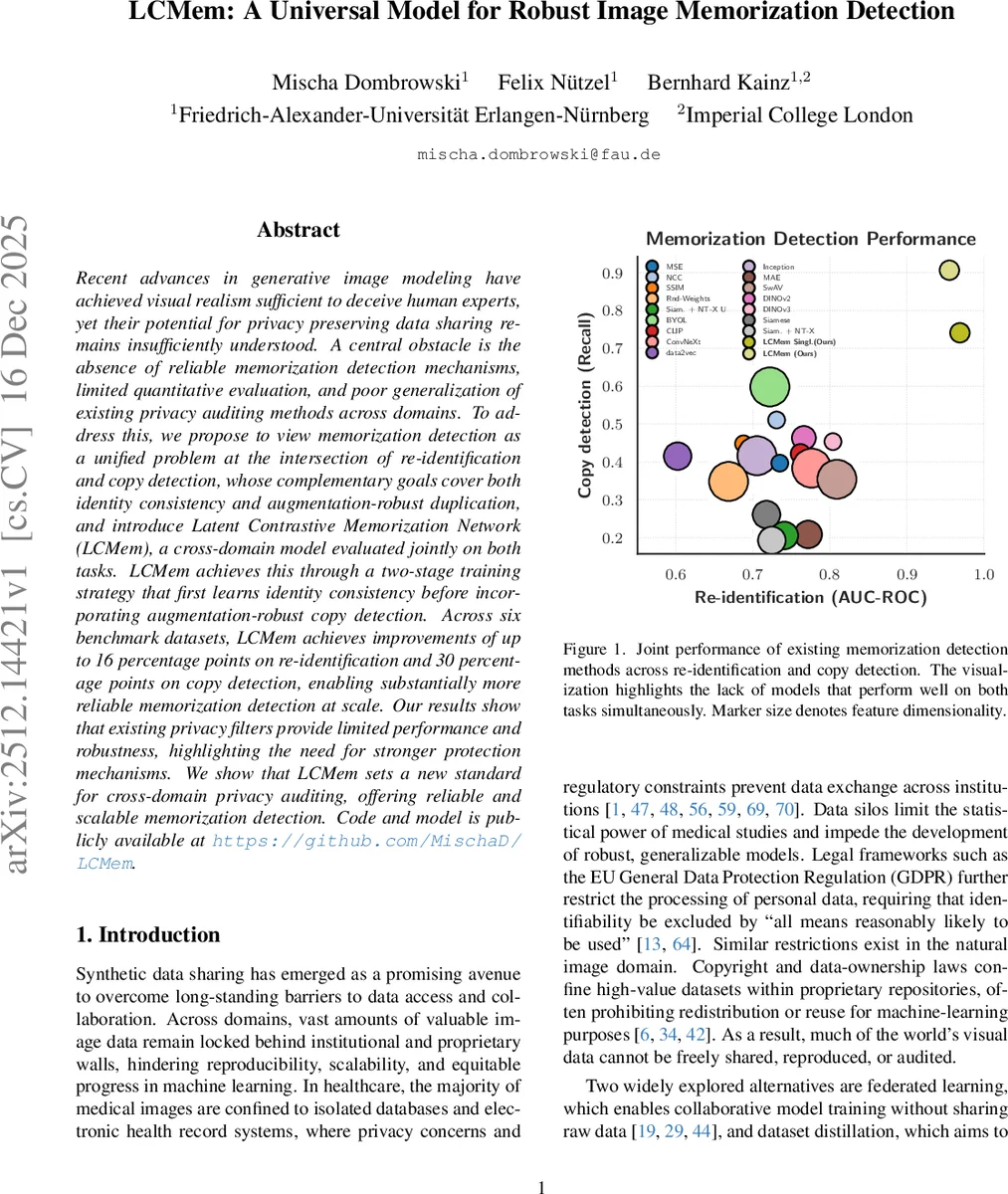
LCMem은 재식별과 복제 검출을 하나의 통합 과제로 정의하고, 잠재 공간에서 두 단계 학습(재식별 → 증강 강건 복제 검출)을 수행한다. ConvNeXt‑Tiny 기반 시암쌍둥이 네트워크와 결합된 대조·이진 손실을 이용해 6개 데이터셋에서 재식별 AU‑ROC를 최대 16%, 복제 검출 Recall을 최대 30% 향상시켰다. 공개 코드와 모델은 다양한 도메인(의료·자연 이미지)에서 프라이버시 감사에 활용 가능하다.
상세 분석
본 논문은 최근 고해상도 이미지 생성 모델이 실제 데이터와 구분이 어려울 정도의 품질을 달성함에 따라, 생성된 이미지가 원본을 ‘기억’하고 복제하는 위험성을 강조한다. 기존의 기억 탐지 방법은 재식별(두 이미지가 동일 인스턴스인지 판단)과 복제 검출(증강된 이미지가 원본과 연결되는지 판단)을 별도 문제로 다루며, 단일 데이터셋에만 최적화돼 도메인 간 일반화가 미흡했다. 저자들은 이 두 과제를 보완적 목표로 보는 통합 문제를 제안하고, 이를 해결하기 위한 모델 LCMem을 설계했다.
핵심 설계는 (1) 잠재 공간 활용이다. 사전 학습된 LDM(autoencoder)인 SDv2를 이용해 이미지 → 저차원 latent(z)으로 변환하고, 이 latent을 그대로 입력으로 사용한다. 이는 고해상도 이미지의 메모리 부담을 64배 이상 감소시켜 대규모 배치 학습을 가능하게 하고, 노이즈와 고주파 성분을 자동으로 제거해 인스턴스 식별에 집중할 수 있게 한다.
(2) 두 단계 학습 전략이다. 첫 단계에서는 깨끗한 latent 쌍만을 사용해 재식별에 최적화한다. 여기서는 이진 교차 엔트로피 손실(BCE)만을 적용해 동일 인스턴스 여부를 정확히 학습한다. 두 번째 단계에서는 이미지 공간에서 강도 높은 증강(회전, 색상 변형 등)을 적용하고, 이를 다시 latent으로 인코딩해 복제 검출 능력을 강화한다. 이때는 **대조 손실(NT‑Xent)**을 결합해 동일 인스턴스의 임베딩을 서로 가깝게, 다른 인스턴스는 멀게 만든다. 두 손실을 가중치 α로 조절한 복합 손실 L_final = α·L_u + (1−α)·L_fc는 재식별 정확도와 복제 강건성을 동시에 최적화한다.
아키텍처는 ConvNeXt‑Tiny를 시암쌍둥이 백본으로 채택해, 기존 ResNet 기반보다 파라미터 효율성과 성능을 모두 개선한다. 특징 벡터 u와 u′의 절대 차이를 MLP에 입력해 0‑1 확률을 출력하므로, 사전 계산된 실 이미지 특징을 저장해 두면 복제 검출 시 쿼리‑대‑갤러리 방식으로 빠른 검색이 가능하다.
실험에서는 의료(예: ChestX‑Ray, OCT)와 자연 이미지(CIFAR‑10, ImageNet‑subset) 등 6개 데이터셋을 사용해 재식별 AU‑ROC와 복제 검출 Recall을 평가했다. LCMem은 최고 16%p AU‑ROC, 30%p Recall 향상을 기록했으며, 기존 프라이버시 필터(예: MSE, SSIM, CLIP 등)는 두 지표 모두에서 크게 뒤처졌다. 또한, 생성된 합성 이미지에 대해 사전 학습된 조건부 diffusion 모델을 이용해 기억률을 측정했는데, LCMem은 높은 재식별 정확도로 실제 메모리 사례를 효과적으로 탐지했다.
한계점으로는 (i) 잠재 공간에 직접 적용할 수 없는 이미지‑레벨 증강이 제한적이며, (ii) 라벨이 없는 데이터셋에서는 완전한 재식별 학습이 어려워 성능 저하가 발생한다는 점을 언급한다. 향후 연구에서는 멀티‑모달 잠재 표현(텍스트‑이미지)과 라벨‑프리 클러스터링을 결합해 라벨이 없는 도메인에서도 강건한 기억 탐지를 구현하려는 방향을 제시한다.
전반적으로 LCMem은 기억 탐지를 재식별과 복제 검출이라는 두 축을 동시에 최적화한 최초의 통합 모델이며, 잠재 공간 기반 고효율 학습과 두 단계 대조 학습이라는 혁신적인 설계가 다양한 도메인에 걸친 프라이버시 감사에 실용적인 솔루션을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기