AI 생산성 지수 APEX: 전문가 업무 벤치마크 최신판
초록
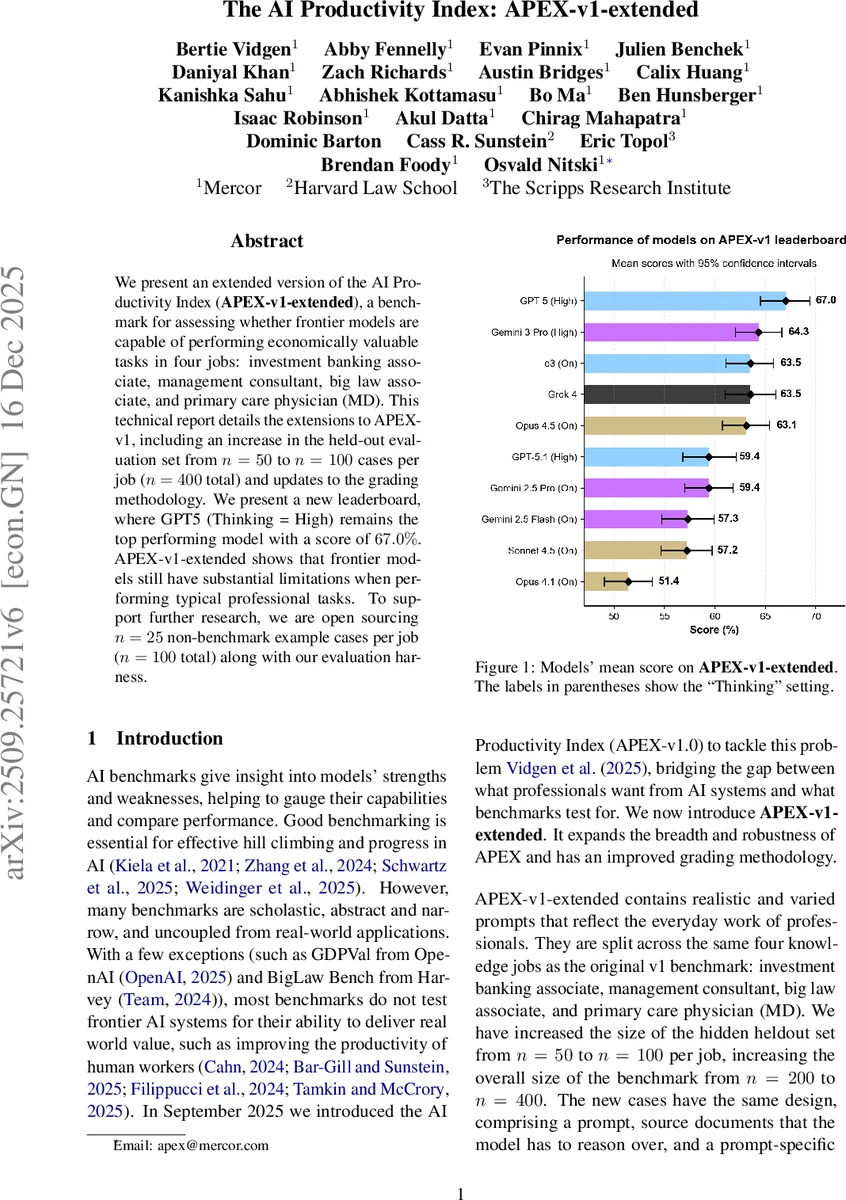
APEX‑v1‑extended는 투자은행, 경영컨설팅, 대형법무, 내과의사 네 직무에 대한 400개의 실제 업무 사례를 포함한 확장 벤치마크이다. 평가 방식은 단일 LLM 심판(Gemini 2.5 Flash)으로 8회 반복 응답을 평균내고 95 % 신뢰구간을 제시한다. 최신 모델 중 GPT‑5(Thinking = High)가 67 % 점수로 1위를 차지했으며, 여전히 직무별 과제 수행에 한계가 있음을 보여준다.
상세 분석
APEX‑v1‑extended는 기존 APEX‑v1.0에 비해 평가 셋을 2배 확대해 총 400개의 비공개 사례를 제공한다. 각 직무별 사례 수는 100개이며, 공개용 개발 셋은 직무당 25개씩 총 100개를 CC‑BY 라이선스로 공개한다. 데이터 구성은 평균 14.8개의 평가 기준과 3.7개의 소스 문서를 포함하며, 프롬프트 길이는 평균 358 토큰에 달한다. 전문가 선정 과정은 Mercor 플랫폼을 통해 7년 이상의 현업 경험을 가진 137명의 전문가를 확보했으며, 이들은 직접 프롬프트와 루브릭을 작성하고 다단계 리뷰를 거쳐 품질을 보증한다. 소스 문서는 PDF, XLSX, TXT 등 다양한 포맷을 허용하고 토큰 길이 제한은 100 000 토큰이다.
평가 방법론의 핵심 변화는 (1) 다중 LLM 심판 대신 단일 LLM인 Gemini 2.5 Flash를 사용해 평가 일관성을 높인 점, (2) 각 프롬프트에 대해 모델 응답을 8회 수집해 평균값을 채점에 활용함으로써 변동성을 감소시킨 점, (3) 95 % 신뢰구간과 표준편차를 함께 보고해 통계적 유의성을 강화한 점이다. Friedman 전체 테스트(p < 0.000001)와 Bonferroni 보정 후의 쌍별 t‑검정 결과, 모델 간 차이는 대부분 통계적으로 유의하였다.
리더보드에서는 GPT‑5(Thinking = High)가 전체 평균 67 %로 1위이며, 법무 분야에서는 77.9 %라는 높은 점수를 기록한다. 반면 투자은행 직무에서는 최고 점수조차 63 %에 머물러, 직무 난이도와 요구되는 전문 지식 차이가 모델 성능에 큰 영향을 미침을 시사한다. Z‑스코어 분석에서는 GPT‑5가 0.50으로 두 번째 모델인 Opus 4.5(Thinking = On)보다 현저히 앞서며, 특히 가장 어려운 과제에서 강점을 보인다.
한계점으로는 (①) 평가 기준이 인간 전문가가 설계했음에도 불구하고 여전히 주관적 요소가 남아 있을 가능성, (②) 단일 LLM 심판이 편향을 내포할 위험, (③) 실제 현업에서 요구되는 다중 턴 대화나 협업 상황을 반영하지 못한다는 점을 들 수 있다. 향후 연구는 다중 심판 체계 도입, 멀티턴 시나리오 확장, 그리고 모델‑인간 협업 효율성을 정량화하는 메트릭 개발이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기