엑소투에고 외부 시각 지식으로 강화한 첫인칭 비디오 이해
초록
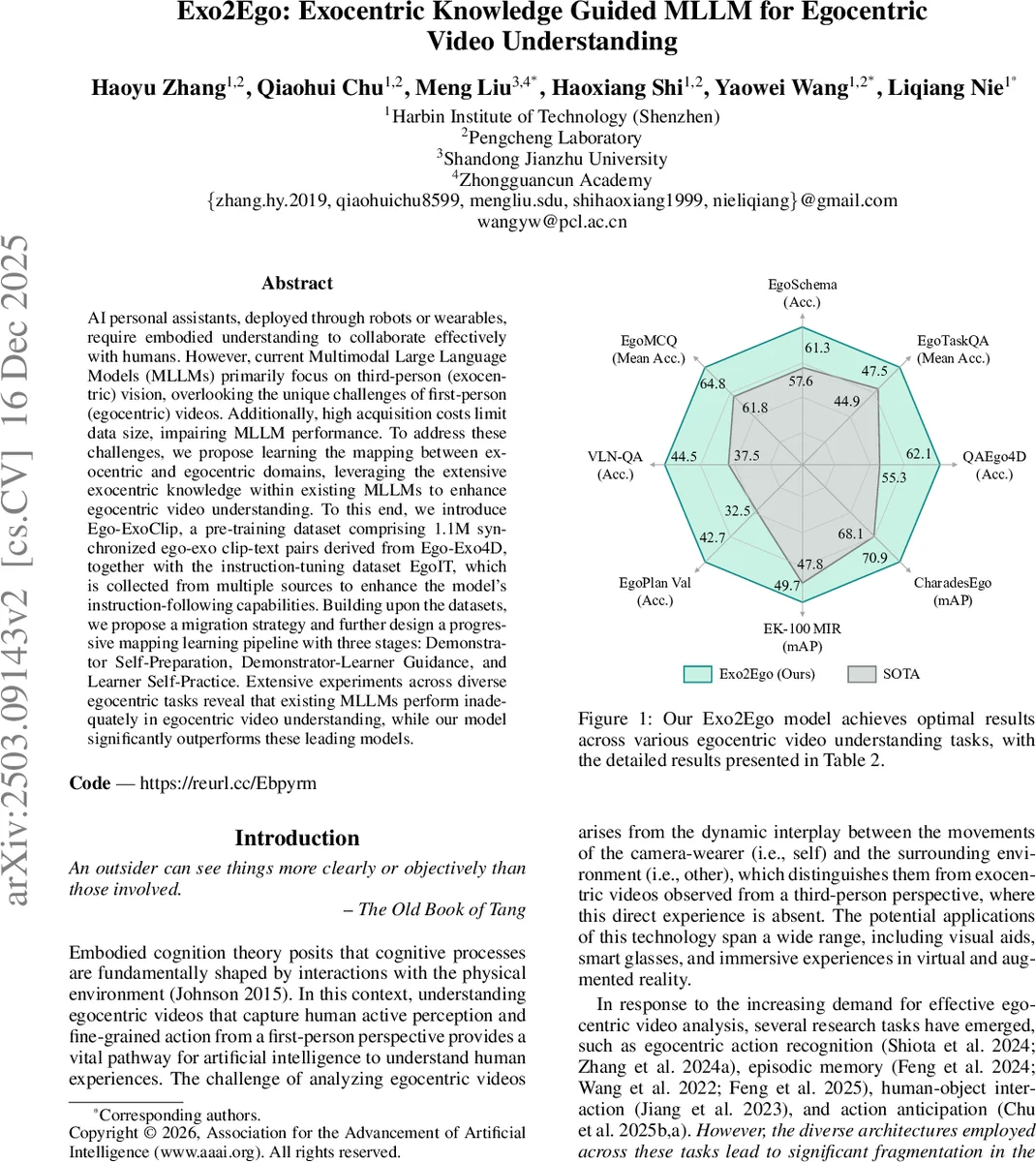
본 논문은 기존 멀티모달 대형 언어 모델(MLLM)이 주로 제3자 시점(엑소센트릭) 영상에 초점을 맞춘 한계를 극복하고자, 방대한 엑소센트릭 지식을 활용해 첫인칭(에고센트릭) 비디오 이해 능력을 향상시키는 프레임워크인 Exo2Ego를 제안한다. 1.1 백만 개의 동기화된 에고‑엑소 클립‑텍스트 쌍으로 구성된 사전학습 데이터셋 Ego‑ExoClip과, 다양한 지시‑튜닝 샘플을 포함한 EgoIT를 구축하였다. 이후 시연자(Self‑Preparation), 시연자‑학습자(Guidance), 학습자(Self‑Practice)라는 3단계 매핑 학습 파이프라인을 설계해, 엑소센트릭 비디오와 에고센트릭 비디오 사이의 변환 함수를 순환 일관성 및 KL 손실을 통해 학습한다. 실험 결과, 기존 MLLM 대비 다양한 에고센트릭 벤치마크에서 현저히 높은 성능을 달성한다.
상세 분석
Exo2Ego는 “시연자‑학습자” 메타포를 도입해 인간이 타인의 행동을 관찰하고 자신의 경험에 매핑하는 인지 과정을 모델링한다. 이 접근법은 두 가지 핵심 장점을 제공한다. 첫째, 매핑이 학습되면 downstream 작업에서 별도의 엑소센트릭‑에고센트릭 데이터 교환이 필요 없어 데이터 편향과 추가 연산 비용을 크게 줄인다. 둘째, 인간의 시점 불변성을 활용함으로써 모델의 일반화 능력이 강화되어, 제한된 에고센트릭 데이터만으로도 다양한 태스크에 적용 가능하다.
데이터 측면에서 Ego‑ExoClip은 Ego‑Exo4D에서 동시 촬영된 5,035개의 비디오 그룹 중 2,925그룹을 선별해 1.1 M개의 클립‑텍스트 쌍을 생성한다. 타임스탬프 기반 내러션을 클립 수준으로 확장하기 위해 평균 템포 β와 스케일 파라미터 α(=1.92 s)를 이용해 시작·종료 시점을 정의한다. 이는 내러션이 하나의 클립에만 매핑되도록 경계 조건을 설정함으로써 텍스트‑비디오 정합성을 확보한다.
EgoIT는 약 60만 개의 지시‑튜닝 샘플을 네 가지 요소(비디오 경로, 작업 지시, 질문, 답변)로 표준화하고, GPT‑4o를 활용해 각 데이터셋당 10가지 변형 지시문을 생성한다. 작업은 행동 인식, 질의응답, 캡셔닝으로 구분되며, EGTEA, Something‑Something‑V2, EgoTimeQA, OpenEQA, EgoExoLearn 등 기존 에고센트릭 데이터셋을 재활용한다.
학습 파이프라인은 초기화 단계에서 엑소센트릭과 에고센트릭 각각의 비주얼 인코더를 대규모 웹 비디오·이미지‑텍스트 데이터와 EgoClip을 이용해 사전학습한다. 이때 LLM 파라미터는 고정하고 인코더만 최적화한다.
Stage 1(시연자 Self‑Preparation)에서는 엑소센트릭 인코더를 Ego‑ExoClip의 엑소 클립‑텍스트 쌍에 VTG(vision‑grounded text generation) 손실로 미세조정한다. 이는 시연자가 에고‑엑소 동기 데이터에 익숙해지도록 만든다.
Stage 2(시연자‑학습자 Guidance)에서는 시연자 인코더를 고정하고, 에고 인코더와 매핑 함수 F:X→Y, G:Y→X를 동시에 학습한다. 매핑은 순환 일관성 손실 L_CCL = E_x
댓글 및 학술 토론
Loading comments...
의견 남기기