텍스트가 승리한다: 시각 정보가 의료 의사결정에 미치는 역효과
초록
본 논문은 대형 멀티모달 언어 모델(MLLM)이 알츠하이머 단계 구분과 흉부 X‑ray 다중 질환 분류 같은 의료 의사결정(MDM) 과제에서 시각 입력만으로는 충분히 성능을 발휘하지 못한다는 사실을 실증한다. 텍스트 전용 추론이 일관적으로 최고 성능을 보였으며, 저자는 인‑컨텍스트 학습, 이미지 캡셔닝 후 텍스트 추론, 비전 탑의 소수 샷 파인튜닝 등 세 가지 개선 전략을 제안한다.
상세 분석
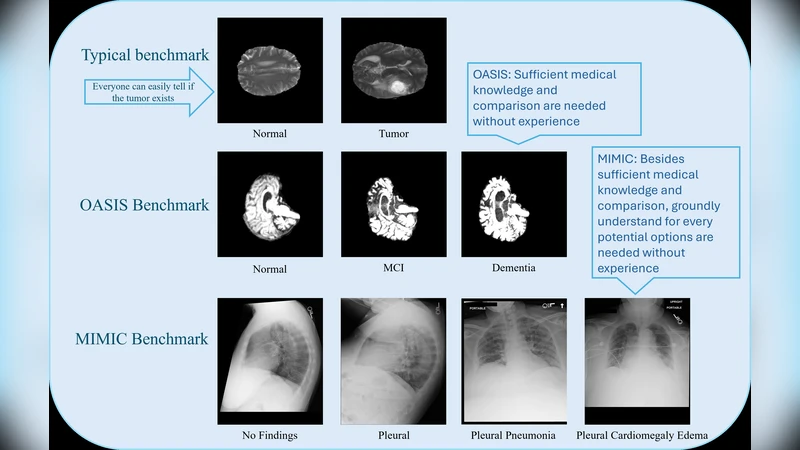
이 연구는 두 개의 고난이도 의료 데이터셋을 선택해 MLLM의 한계를 정량적으로 평가한다. 첫 번째는 알츠하이머병(AD) 3단계(정상, 경도인지장애, 치매) 분류로, MRI 혹은 PET 영상에서 나타나는 미세한 구조적·대사적 차이를 구분해야 한다. 두 번째는 MIMIC‑CXR 데이터베이스의 흉부 X‑ray 이미지에 대해 14개의 비상호배타적 질환 라벨을 동시에 예측하는 다중라벨 분류이다. 두 과제 모두 시각적 특징이 미묘하고, 임상적 판단에는 환자의 병력·증상·검사 결과 등 텍스트 정보가 핵심적인 역할을 한다는 점에서 멀티모달 접근의 필요성을 가정한다.
실험에 사용된 모델은 최신 MLLM(예: LLaVA, MiniGPT‑4 등)이며, 각각 ‘텍스트 전용’, ‘시각 전용’, ‘시각+텍스트’ 세 가지 입력 설정으로 평가한다. 결과는 놀랍게도 텍스트 전용 설정이 가장 높은 정확도·F1 점수를 기록했으며, 시각 정보를 추가한 멀티모달 설정은 종종 성능 저하를 보였다. 특히 AD 단계 구분에서는 시각 입력이 오히려 혼동을 일으켜 텍스트만 사용할 때보다 57% 낮은 정확도를 보였고, MIMIC‑CXR에서도 평균 AUROC이 0.020.04 정도 감소하였다. 이는 현재 MLLM이 의료 영상의 미세한 변화를 ‘그라운드’ 수준으로 이해하지 못하고, 텍스트 기반 추론에 비해 시각 정보를 효과적으로 통합하지 못한다는 증거이다.
성능 향상을 위해 저자는 세 가지 전략을 탐색한다. 첫째, ‘인‑컨텍스트 학습’으로 이유(annotation)와 함께 제공된 예시를 프롬프트에 삽입해 모델이 추론 과정을 명시적으로 학습하도록 유도한다. 이 방법은 특히 텍스트 전용 상황에서 정확도를 23% 끌어올렸다. 둘째, ‘비전 캡셔닝’ 접근법으로 이미지 → 텍스트 설명 → 텍스트 전용 모델 순서로 파이프라인을 재구성한다. 이미지 캡션이 의료 전문 용어와 정확히 매핑되지 않아 제한적이었지만, 일부 라벨(예: ‘심장 비대’)에서는 성능 회복 효과가 관찰되었다. 셋째, ‘비전 탑 소수 샷 파인튜닝’으로 제한된 라벨링 데이터(각 클래스당 510장)를 이용해 비전 인코더를 가볍게 재학습시킨다. 이 방법은 특히 AD 데이터셋에서 시각 전용 모델의 정확도를 6% 이상 상승시켰으며, 멀티모달 전체 파이프라인에서도 소폭 개선을 가져왔다.
전반적으로 연구는 현재 MLLM이 ‘시각적 근거’를 충분히 활용하지 못하고, 텍스트 기반 지식에 의존하는 경향이 강함을 밝힌다. 이는 의료 현장에서 이미지와 텍스트가 동등하게 중요한 상황에서 위험 요소가 될 수 있다. 저자는 향후 비전‑언어 정렬, 의료 전문 캡션 데이터 확대, 그리고 멀티모달 사전학습 목표를 재설계하는 방향을 제시한다.