소규모 배치로 언어 모델 훈련과 최적화
초록
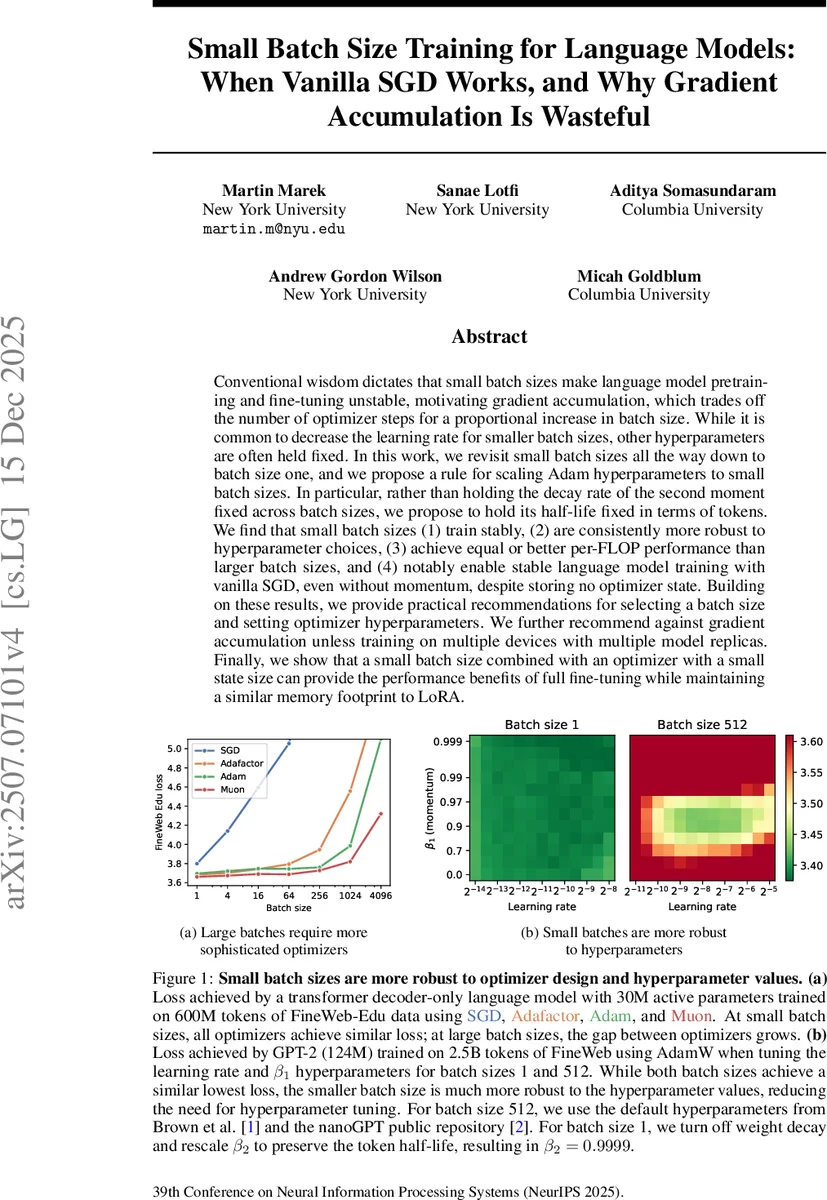
이 논문은 배치 크기를 1까지 줄였을 때도 안정적인 언어 모델 학습이 가능함을 보이며, Adam의 두 번째 모멘트 감쇠율을 “토큰 반감기” 기준으로 스케일링하는 규칙을 제안한다. 작은 배치에서는 학습이 더 안정적이고 하이퍼파라미터에 강건하며, FLOP당 성능이 크게 떨어지지 않는다. 특히 모멘트와 가중치 감쇠가 없는 순수 SGD조차도 경쟁력을 갖게 되며, 메모리 사용량을 크게 절감한다. 저자는 그라디언트 누적을 대부분의 경우 비추천하고, 메모리 효율적인 미세조정에 Adafactor와 소규모 배치를 결합할 것을 권고한다.
상세 분석
본 연구는 기존의 “큰 배치가 안정성을 보장한다”는 통념을 근본적으로 재검토한다. 핵심 아이디어는 배치 크기가 작아질수록 Adam 옵티마이저의 β₂(두 번째 모멘트 감쇠율)를 고정하는 대신, 토큰 수 기준의 반감기(t₁/₂)를 일정하게 유지하는 것이다. 반감기는 βⁿ = ½ 를 만족하는 n을 토큰 수 B·T 로 변환한 값으로, 이를 일정하게 유지하면 작은 배치에서도 과거 그래디언트가 지나치게 오래 유지되지 않아 학습이 발산하지 않는다. 실험에서는 배치 1부터 4096까지 다양한 크기로 30M~1.3B 파라미터 모델을 FineWeb‑Edu와 C4 데이터셋에 적용했으며, β₂를 t₂ = 10M 토큰 정도로 고정하면 배치 1에서도 손실이 안정적으로 감소한다는 것을 확인했다.
또한, 작은 배치에서는 학습 스텝 수가 늘어나므로 학습률을 크게 조정할 필요가 없으며, β₁(첫 번째 모멘트)와 학습률에 대한 민감도가 크게 감소한다. 이는 “학습률‑배치 크기 선형 스케일링” 규칙이 큰 배치에만 유효하고, 작은 배치에서는 오히려 과도한 학습률이 불안정을 초래한다는 점과 일치한다.
특히 주목할 점은 순수 SGD(모멘텀·가중치 감쇠 없이)도 배치 1에서 Adam과 거의 동일한 수렴 속도와 최종 손실을 보였다는 것이다. 이는 작은 배치에서는 그래디언트 노이즈가 충분히 큰데 반해, 큰 배치에서는 노이즈가 억제돼 모멘텀과 복잡한 적응형 스케줄링이 필수적이라는 기존 가설을 반박한다. 메모리 측면에서도 SGD는 옵티마이저 상태를 전혀 저장하지 않으므로, 대규모 모델을 동일한 GPU 메모리 한도 내에서 학습할 수 있다.
Adafactor와의 비교에서도, 소규모 배치와 결합했을 때 Adafactor는 Adam 대비 메모리 사용량을 파라미터 수의 O(d₁+d₂) 로 줄이면서도 성능 저하가 거의 없었다. 이는 미세조정 단계에서 LoRA와 같은 파라미터 효율적 기법과 메모리 효율을 동시에 달성할 수 있음을 시사한다.
마지막으로, 그라디언트 누적은 “마이크로 배치를 여러 번 합쳐 큰 배치를 흉내 내는” 방식이지만, 이는 누적된 그래디언트를 저장해야 하므로 메모리 오버헤드가 발생한다. 실험 결과, 동일한 토큰 수와 FLOP를 기준으로 할 때, 누적 없이 작은 배치를 직접 사용하는 것이 학습 속도와 안정성 모두에서 우수했다. 따라서 다중 GPU 환경에서 모델 복제(parallelism)를 활용하지 않는 한, 그라디언트 누적은 비효율적이라고 결론짓는다.
이러한 발견은 언어 모델 훈련 파이프라인을 단순화하고, 메모리 제약이 있는 환경에서도 대규모 모델을 효율적으로 학습할 수 있는 새로운 설계 지침을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기