극심한 데이터 불균형을 극복하는 새로운 회귀 학습법 CISIR
초록
상세 분석
본 논문은 회귀 분석에서 발생하는 ‘극심한 불균형(Highly Imbalanced)’ 문제, 즉 데이터의 불균형 비율이 1,000을 넘어서는 극한 상황에서의 예측 성능 저하를 다룹니다. 특히 태양 입자(SEP) 이벤트의 강도 예측과 같이, 발생 빈도는 매우 낮지만 발생 시 막대한 피해를 줄 수 있는 ‘희귀하지만 중요한’ 데이터를 다룰 때 발생하는 기술적 한계를 정밀하게 분석합니다.
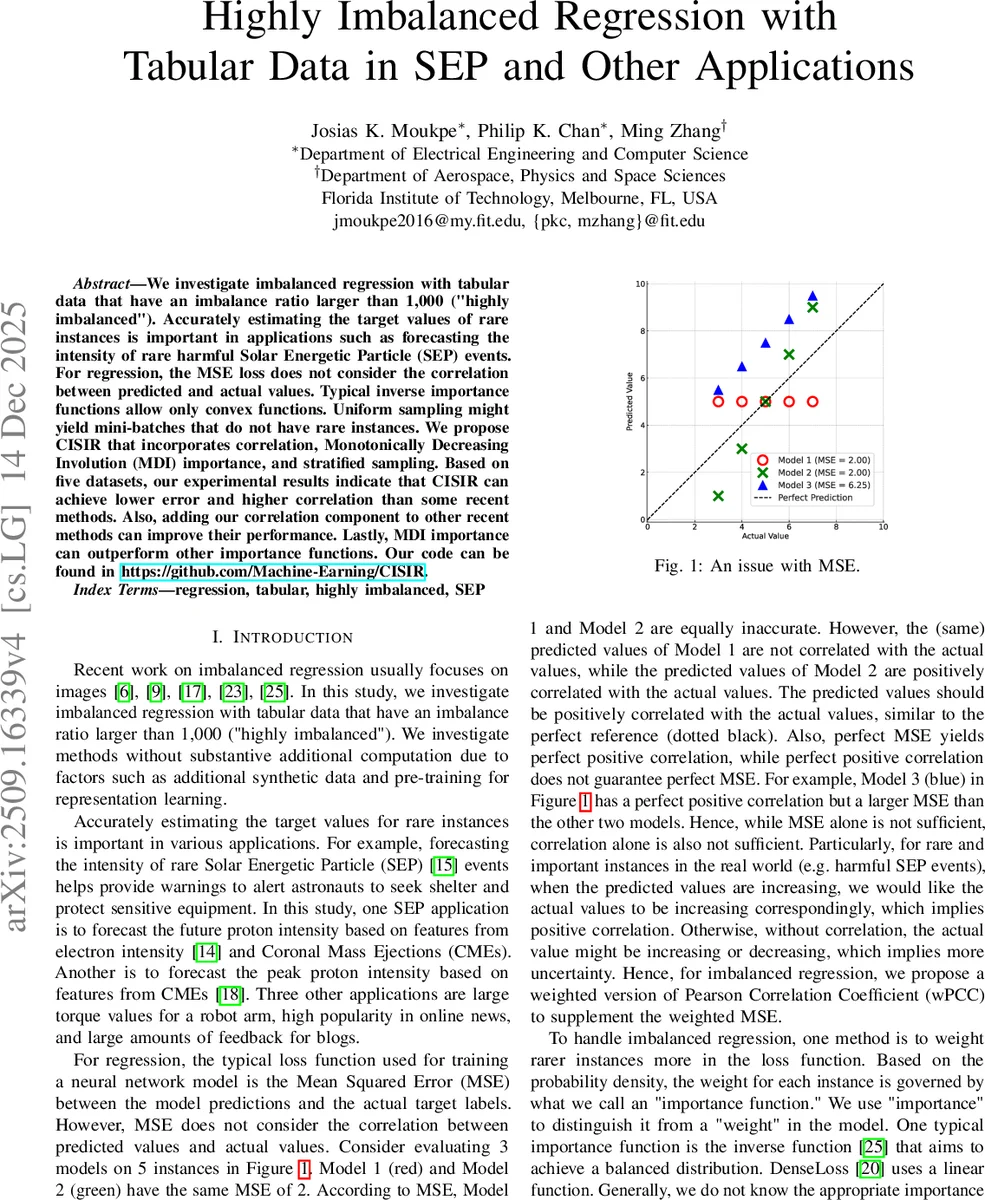
기존 연구들의 한계점은 크게 세 가지로 요약됩니다. 첫째, 가장 널리 사용되는 MSE(Mean Squared Error) 손실 함수는 예측값과 실제값 사이의 수치적 차이만을 최소화할 뿐, 두 값 사이의 통계적 상관관계(Correlation)를 고려하지 못합니다. 이는 예측값이 실제값의 변화 추세를 따르고 있는지 반영하지 못하게 만듭니다. 둘째, 불균형 해소를 위해 사용되는 기존의 역중도(Inverse Importance) 함수들은 주로 볼록 함수(Convex functions) 형태에 국한되어 있어, 복잡하고 비선형적인 데이터 분포를 효과적으로 반영하기 어렵습니다. 셋째, 학습 시 사용하는 유니폼 샘플링(Uniform sampling) 방식은 미니 배치(Mini-batch) 구성 시 희귀 데이터가 포함될 확률이 매우 낮아, 모델이 희귀 사례의 특징을 학습할 기회 자체를 상실하게 만듭니다.
이를 해결하기 위해 저자들은 CISIR(Correlation, Importance, and Stratified sampling for Imbalanced Regression)을 제안합니다. CISIR은 세 가지 핵심 요소를 통합합니다. 우선, 예측값과 실제값의 상관관계를 손실 함수에 직접 반영하여 예측의 경향성을 높였습니다. 특히 이 상관관계 컴포넌트는 모듈식으로 설계되어 기존의 다른 최신 알고리즘에 결합했을 때도 성능을 향상시키는 ‘플러그인’ 역할을 수행할 수 있습니다. 다음으로, MDI(Monotonically Decreasing Involution) 중요도 함수를 도입하여 기존의 제약이 많았던 중요도 부여 방식의 한계를 극복했습니다. 마지막으로, 층화 추출(Stratified sampling)을 통해 학습 과정에서 희귀 데이터가 소외되지 않도록 보장합니다. 이러한 통합적 접근은 단순한 오차 감소를 넘어, 데이터의 구조적 특징을 학습에 반영할 수 있는 새로운 패러다임을 제시합니다.
현대 데이터 과학의 핵심 과제 중 하나는 데이터의 분포가 극도로 불균형할 때 어떻게 희귀한 사례를 정확하게 예측할 것인가 하는 점입니다. 특히 태양 입자(SEP) 이벤트의 강도 예측과 같이, 발생 빈도는 매우 낮지만 발생 시 막대한 피해를 줄 수 있는 ‘희귀하지만 중요한’ 데이터를 다룰 때, 데이터 불균형 비율이 1,000을 넘어서는 극심한 불균형(Highly Imbalanced) 상황이 빈번하게 발생합니다. 본 논문은 이러한 극한의 불균형 환경에서 기존 회귀 모델들이 겪는 치명적인 한계를 분석하고, 이를 혁신적으로 해결할 수 있는 새로운 프레임워크인 CISIR을 제시합니다.
기존 연구들의 한계점은 매우 구체적입니다. 첫째, 표준적인 MSE(Mean Squared Error) 손실 함수는 예측값과 실제값 사이의 절대적인 거리만을 측정합니다. 이는 예측값이 실제값의 변화 추세나 상관관계를 따르고 있는지(Correlation)를 반영하지 못하므로, 희귀 사례의 패턴을 학습하는 데 한계가 있습니다. 둘째, 불균형 해소를 위해 사용되는 기존의 역중도(Inverse Importance) 함수들은 주로 볼록 함수 형태의 가중치 부여에 국한되어 있어, 복잡하고 비선형적인 데이터 분포를 효과적으로 처리하지 못합니다. 셋째, 학습 시 사용하는 유니폼 샘플링(Uniform sampling) 방식은 미니 배치(Mini-batch)를 구성할 때 희귀 데이터가 포함될 확률이 매우 낮아, 모델이 희귀 사례의 특징을 학습할 기회 자체를 박탈당하는 문제를 야기합니다.
이러한 문제를 해결하기 위해 제안된 CISIR(Correlation, Importance, and Stratified sampling for Imbalanced Regression)은 세 가지 핵심 메커니즘을 통합합니다.
첫째, ‘상관관계(Correlation)’ 요소를 손실 함수에 도입하였습니다. 이는 단순히 오차를 줄이는 것을 넘어, 예측값과 실제값 사이의 통계적 연관성을 극대화하도록 모델을 유도합니다. 주목할 점은 이 상관관계 컴포넌트가 모듈식으로 설계되어, 기존의 다른 최신 회귀 알고리즘에 결합했을 때도 성능 향상을 이끌어낼 수 있다는 점입니다.
둘째, ‘MDI(Monotonically Decreasing Involution) 중요도’ 함수를 제안합니다. 이는 기존의 제약이 많았던 중요도 함수들을 넘어, 데이터의 희귀도에 따라 보다 유연하고 효과적인 가중치를 부여할 수 있게 합니다. 실험을 통해 MDI가 기존의 다른 중요도 함수들보다 우수한 성능을 보임을 입증하였습니다.
셋째, ‘층화 추출(Stratified sampling)’ 전략을 적용하였습니다. 이는 학습 데이터의 분포를 고려하여 미니 배치를 구성함으로써, 극심한 불균형 상황에서도 희귀 데이터가 학습 과정에 충분히 노출되도록 보장합니다.
실험 결과는 매우 고무적입니다. 다섯 가지의 다양한 데이터셋을 대상으로 진행된 실험에서, CISIR은 기존의 최신(SOTA) 방법론들보다 더 낮은 오차율과 더 높은 상관계수를 기록했습니다. 특히 제안된 상관관계 컴포넌트의 범용성과 MDI 중요도 함수의 우수성이 확인되었습니다. 결론적으로 본 연구는 극심한 데이터 불균형을 가진 정형 데이터(Tabular Data) 환경에서, 단순한 오차 최소화를 넘어 데이터의 구조적 관계를 학습할 수 있는 새로운 지평을 열었다고 평가할 수 있습니다.
댓글 및 학술 토론
Loading comments...
의견 남기기