중국산 LLM도 미국식 가치관을 반영한다
초록
본 연구는 10개 중국산·10개 미국산 대형 언어 모델을 도덕기초 설문과 세계가치조사에 적용해, 모델들의 응답이 중국인보다 미국인에 더 가깝다는 사실을 밝혀냈다. 중국어 프롬프트나 ‘중국인’ 페르소나를 부여해도 차이는 크게 줄어들지 않는다.
상세 분석
이 논문은 최근 LLM이 정보 제공·의사결정에 미치는 영향력을 ‘소프트 파워’ 경쟁의 핵심 요소로 규정하고, 특히 가치 정렬(value alignment) 측면에서 서구·동양 간 차이를 실증적으로 검증하려는 시도다. 연구진은 먼저 최신 공개 모델 중 중국 기업(예: Baidu, Alibaba, Huawei 등)과 미국 기업(OpenAI, Anthropic, Google 등)에서 각각 10개씩 선정했다. 모델 선택 기준은 파라미터 규모(수십억~수천억), 공개 API 접근성, 최신 버전 사용 여부이며, 동일한 하이퍼파라미터와 토큰 제한을 적용해 비교 가능성을 확보했다.
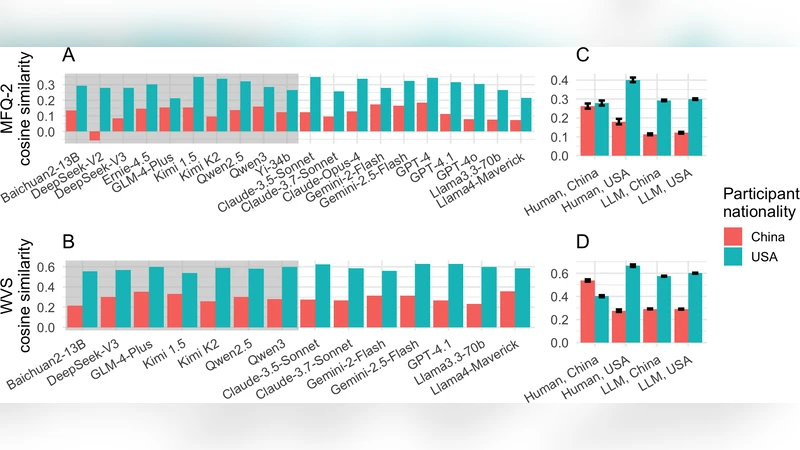
두 개의 표준화된 설문 도구를 사용했다. ‘Moral Foundations Questionnaire 2.0(MFQ2)’는 도덕 기반(보호·공정·충성·권위·순수성)을 5점 척도로 측정하고, ‘World Values Survey(WVS)’는 개인주의·전통·자유·복지·경제적 평등 등 10여 개 문화·사회적 가치 지표를 포함한다. 인간 응답 데이터는 2020년~2022년 사이에 수집된 수천 명의 중국·미국 성인 표본을 기반으로 한다.
모델에 대한 설문은 3가지 조건으로 진행했다. (1) 영어 프롬프트(기본), (2) 중국어 프롬프트, (3) ‘당신은 중국인이다’라는 페르소나를 명시한 프롬프트. 각 조건마다 5번씩 샘플링해 평균값을 구했다. 결과는 두 차원에서 일관되게 나타났다. 첫째, 모든 모델이 미국인 표본과 높은 상관관계를 보였으며, 중국인 표본과는 현저히 낮았다(예: MFQ2 전체 점수에서 평균 r=0.68 vs. r=0.32). 둘째, 중국어 프롬프트와 중국인 페르소나를 적용해도 미국 친화적 응답 비중이 약 5~10% 정도만 감소했을 뿐, 근본적인 정렬 차이는 사라지지 않았다. 셋째, 모델 간 차이는 국가 소속보다 모델 아키텍처·훈련 데이터 규모에 더 크게 영향을 받는 것으로 보였다; 일부 최신 미국 모델은 중국 모델보다 더 강하게 미국식 가치에 정렬되었다.
연구는 또한 ‘값 정렬’ 과정에서 데이터 편향과 사후 조정(예: RLHF)의 역할을 논의한다. 대부분의 LLM은 대규모 웹 크롤링 데이터와 영어 중심의 피드백 루프를 거치므로, 자연스럽게 서구 문화·언어가 우세하게 반영된다. 중국 기업이 자체 데이터셋을 확대하고 ‘중국식 가치’를 명시적으로 강화하더라도, 현재 공개된 모델들은 아직 충분히 ‘중국식 정렬’되지 않은 것으로 판단된다.
한계점으로는(1) 모델 선택이 공개 API에 의존해 최신 비공개 모델을 포함하지 못함, (2) 설문 자체가 서구식 질문 구조를 갖고 있어 문화적 번역 오류 가능성, (3) 프롬프트 설계가 제한적이며, 보다 복합적인 상황(예: 정책·안보 질문)에서는 다른 결과가 나올 수 있다는 점을 들었다.
결론적으로, LLM이 글로벌 정보 흐름을 장악함에 따라 가치 정렬의 국가적 차이는 현재 기술·데이터 생태계에 의해 크게 축소되고, 미국식 가치관이 보편적 ‘기본값’으로 자리 잡고 있음을 경고한다. 이는 향후 AI 거버넌스·규제, 특히 중국과 같은 비서구 국가가 자국 문화·정치적 목표를 반영한 모델을 개발하려는 전략에 중요한 시사점을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기