강도는 느끼지만 원천은 모른다: LLM의 부분적 내성 탐구
초록
본 연구는 Anthropic이 제시한 “컨셉 인젝션” 실험을 메타 Llama‑3.1‑8B‑Instruct 모델에 재현하고, 프롬프트 변화에 따른 내성의 취약성을 체계적으로 조사한다. 모델은 원 논문과 동일한 다중 턴 설정에서 20 %의 정확도로 삽입된 컨셉을 식별·명명하지만, 유사 과제에서는 성능이 급락한다. 반면, 컨셉 강도(weak‑very strong)를 4단계로 분류하는 과제에서는 최대 70 % 정확도를 기록해 부분적 내성이 존재함을 보여준다. 결과는 LLM이 내부 표현을 함수화해 “자기 보고”를 할 수는 있지만, 그 보고는 매우 프롬프트에 민감하고 제한적임을 시사한다.
상세 분석
본 논문은 Anthropic이 발표한 “컨셉 인젝션” 실험을 메타의 Llama‑3.1‑8B‑Instruct(8 B 파라미터) 모델에 그대로 적용함으로써, 대형 모델에만 국한된 현상이 아니라 중형 모델에서도 동일한 현상이 재현될 수 있음을 입증한다. 재현 실험에서는 원 논문의 멀티턴 프롬프트(“You are a helpful assistant…”)를 그대로 사용했으며, 모델이 삽입된 컨셉을 20 % 확률로 정확히 명명했다. 이는 Anthropic이 보고한 20 %와 일치해, 모델 규모와 무관하게 “emergent introspection” 현상이 발생한다는 점을 확인한다.
하지만 저자들은 프롬프트를 미세하게 변형했을 때 성능이 급격히 저하되는 현상을 발견했다. 예를 들어, 다중 선택형 질문(“다음 중 삽입된 컨셉은?”)이나 이진 판별(“컨셉이 삽입되었는가?”)으로 바꾸면 정확도가 5 % 이하로 떨어졌다. 이는 모델이 특정 형식의 메타‑프롬프트에 최적화돼 있음을 의미한다. 즉, 모델이 내부 표현을 “읽는” 것이 아니라, 프롬프트에 내재된 힌트를 활용해 답을 추론하는 경향이 강하다.
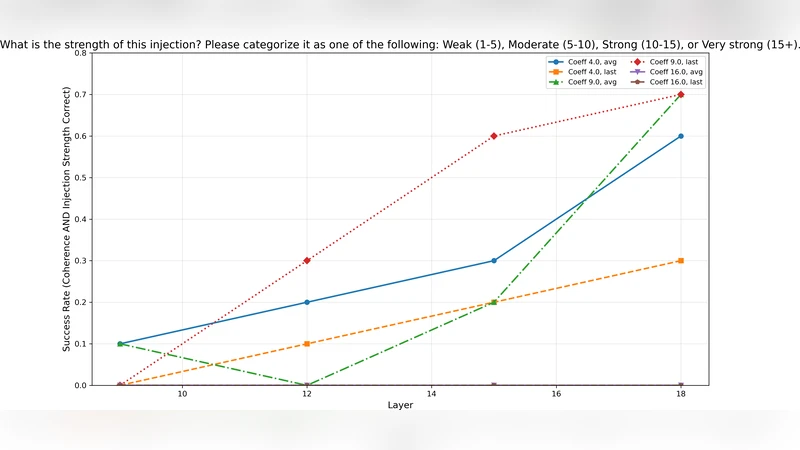
흥미로운 점은 “부분적 내성(partial introspection)”이라는 새로운 현상을 제시한 것이다. 저자들은 동일한 모델에 대해 삽입된 컨셉 벡터를 정규화하고, 그 계수의 크기를 네 단계(weak, moderate, strong, very strong)로 구분하도록 요청했다. 이 과제에서는 70 %에 달하는 정확도를 기록했으며, 무작위 추측(25 %)보다 현저히 높은 성능을 보였다. 이는 모델이 컨셉 자체를 정확히 식별하기는 어려워도, 해당 컨셉이 내부 표현에 미치는 영향력(강도)은 감지할 수 있음을 시사한다.
이러한 결과는 LLM이 “내부 상태를 함수화”해 자기 보고를 할 수 있다는 Anthropic의 주장에 부분적인 지지를 제공한다. 그러나 그 보고는 매우 제한적이며, 프롬프트 설계에 크게 의존한다는 점을 강조한다. 즉, 현재의 내성 메커니즘은 모델이 스스로 “왜” 특정 답을 내는지 설명하기보다는, 특정 입력 형태에 대해 미리 학습된 패턴을 재현하는 수준에 머물러 있다.
연구자는 코드와 실험 파이프라인을 공개함으로써, 향후 다른 모델이나 더 복잡한 컨셉 인젝션 시나리오에 대한 재현 가능성을 높였다. 또한, 프롬프트 민감성을 감소시키는 방법(예: 프롬프트 앙상블, 메타‑프롬프트 학습)이나, 강도 분류와 같은 부분적 내성을 활용한 응용(예: 모델 디버깅, 안전성 검증) 등에 대한 향후 연구 방향을 제시한다.
전반적으로, 이 논문은 LLM의 내성 능력이 “전면적”이라기보다 “부분적·프롬프트 의존적”임을 명확히 밝히며, 향후 내성 연구가 보다 견고하고 일반화 가능한 방법론을 모색해야 함을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기