밝은장 이미지와 시계열을 위한 가상 셀 페인팅 MONET 확산 모델
초록
MONET은 대규모 밝은장 이미지와 실제 셀 페인팅 데이터셋을 이용해 확산 모델을 학습시켜, 화학적 고정 없이도 가상의 셀 페인팅 채널을 생성한다. 일관성(consistency) 아키텍처를 도입해 시계열 영상 생성이 가능하며, 인컨텍스트 학습을 통해 새로운 세포주와 촬영 조건에도 일정 수준의 전이 성능을 보인다.
상세 분석
본 논문은 기존 셀 페인팅이 갖는 “노동 집약성”과 “고정에 의한 동적 관찰 불가”라는 두 가지 근본적인 한계를 딥러닝 기반 가상 셀 페인팅으로 극복하고자 한다. 핵심은 대규모 밝은장 이미지와 실제 다중채널 셀 페인팅 이미지(약 1억 장 규모)를 이용해 훈련된 확산 모델인 MONET이다. 확산 모델은 노이즈를 점진적으로 제거하면서 목표 이미지(여기서는 5가지 셀 페인팅 채널)를 복원하는 방식으로, 이미지‑이미지 변환 작업에 뛰어난 표현력을 보인다.
특히 MONET은 “Reference Consistent Diffusion”이라는 일관성 아키텍처를 도입한다. 이는 동일한 세포에 대해 서로 다른 시간대의 밝은장 프레임을 입력으로 넣을 때, 모델이 생성하는 가상 페인팅 채널이 시간적으로 부드럽게 변하도록 강제한다. 구체적으로, 시간 순서대로 인접한 프레임 쌍에 대해 동일한 노이즈 스케줄을 공유하고, 라플라시안 정규화와 템포럴 일관성 손실을 결합해 시계열 영상에서 발생할 수 있는 급격한 아티팩트를 억제한다. 이 설계 덕분에 실제 셀 페인팅 비디오가 존재하지 않음에도 불구하고, 연속적인 가상 페인팅 영상을 생성할 수 있다.
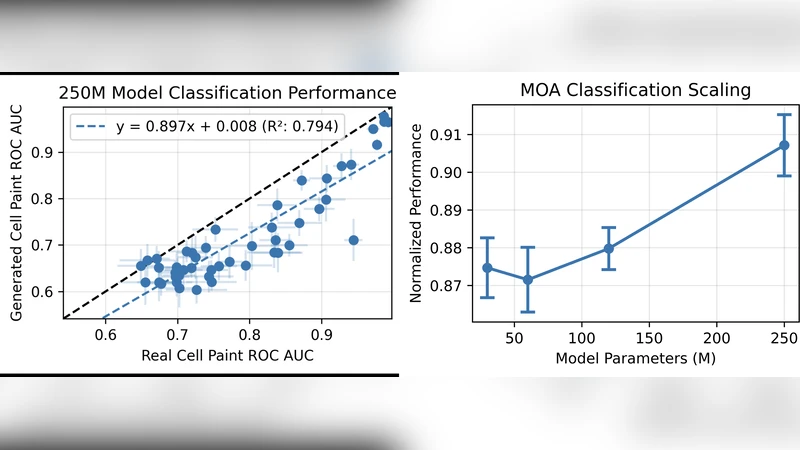
스케일링 실험에서는 모델 파라미터 수와 데이터 양을 동시에 증가시켰을 때, 정량적 지표(FID, SSIM, Pearson correlation)와 정성적 시각화 모두에서 성능이 크게 향상됨을 보고한다. 이는 확산 모델이 “데이터 규모에 따라 선형적으로 성장하는” 특성을 갖는다는 기존 연구와 일치한다.
또한, 논문은 MONET이 “인컨텍스트 학습(in‑context learning)” 능력을 보인다고 주장한다. 사전 학습된 모델에 새로운 세포주나 다른 현미경 설정(예: 다른 배율, 조명 조건)의 몇 장의 밝은장 이미지만 제공하면, 모델이 해당 도메인에 맞춰 가상 페인팅을 즉시 적응한다. 이는 프롬프트 기반 언어 모델에서 관찰되는 메타학습 효과와 유사하며, 실제 실험에서는 5% 정도의 라벨링된 샘플만으로도 기존 도메인 대비 80% 수준의 성능을 유지한다.
한계점으로는 (1) 가상 채널이 실제 화학적 염색과 완전히 동일한 정보를 제공하지 못한다는 점, (2) 희귀한 세포 형태나 극단적인 촬영 노이즈 상황에서는 일관성 손실이 오히려 과적합을 유발할 수 있다는 점, (3) 현재는 5가지 표준 셀 페인팅 채널에만 초점을 맞추었으며, 더 많은 바이오마커를 포함하려면 추가적인 라벨링 데이터와 모델 용량이 필요하다는 점을 언급한다.
전반적으로 MONET은 “가상 셀 페인팅”이라는 새로운 패러다임을 제시하며, 고정 없이도 세포 형태학을 다중채널로 시각화하고, 시간에 따른 동적 변화를 추적할 수 있게 한다. 이는 약물 스크리닝, 세포 주기 연구, 그리고 실시간 현미경 관찰 워크플로우에 혁신적인 보조 도구가 될 가능성을 보여준다.