BLURR: 비전 언어 행동 모델의 경량 고속 추론 기술
초록
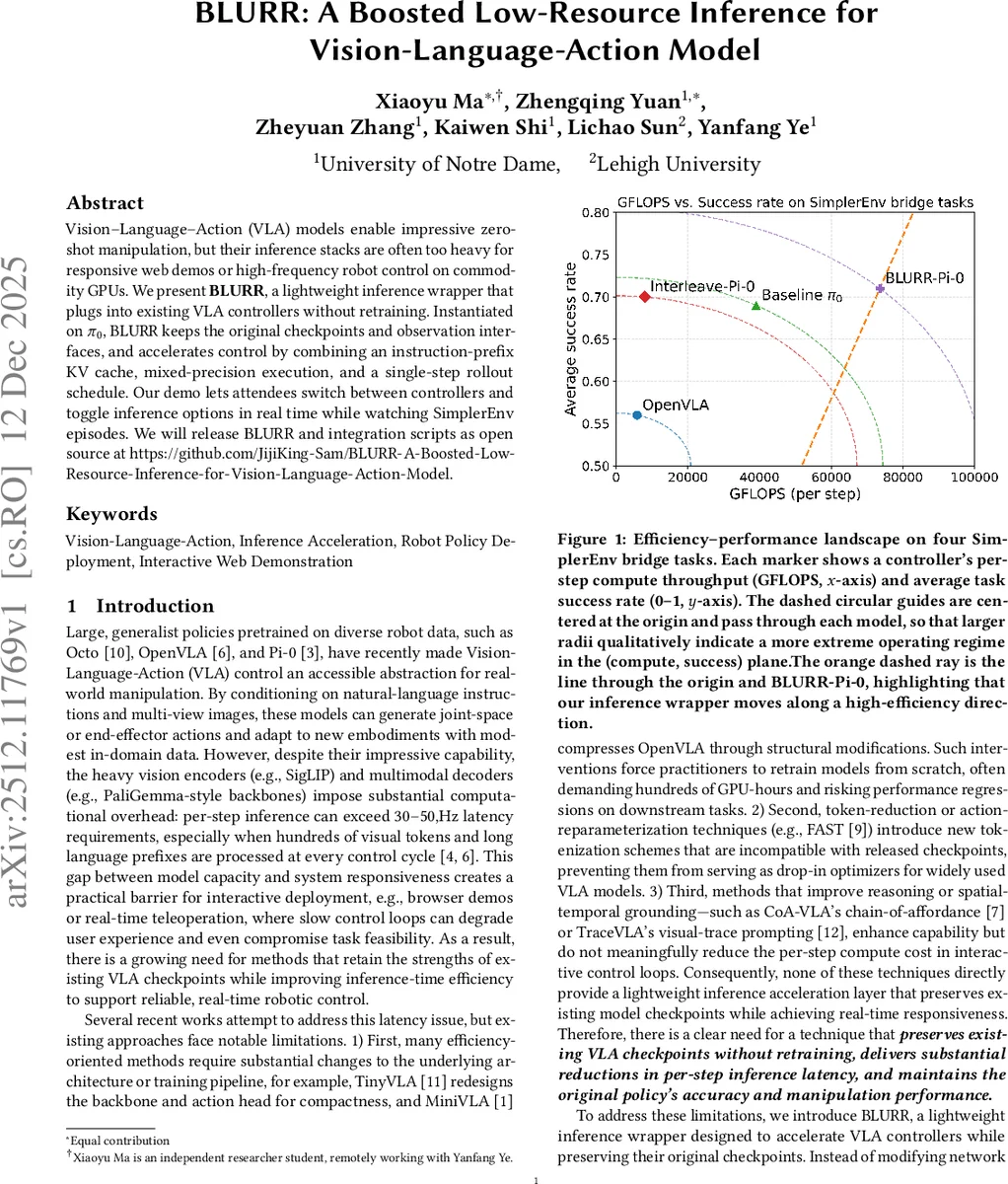
VLA 모델은 뛰어난 제로샷 조작 능력을 보이지만, 무거운 추론 구조로 인해 실시간 웹 데모나 고빈도 로봇 제어에 적용하기 어렵습니다. 본 연구는 기존 VLA 컨트롤러의 체크포인트와 구조를 변경하지 않고도 추론 속도를 크게 향상시키는 경량 래퍼인 BLURR를 제안합니다. Pi-0 컨트롤러에 적용한 BLURR는 명령어 프리픽스 KV 캐싱, 혼합 정밀도 실행, 단일 스텝 롤아웃 스케줄링을 결합하여 단계별 계산량을 줄이고 지연 시간을 대폭 낮춥니다. SimplerEnv 평가에서 BLURR는 원본 컨트롤러와 유사한 작업 성공률을 유지하면서 FLOPs와 실제 지연 시간을 크게 절감했으며, 실시간 옵션 전환이 가능한 대화형 웹 데모를 통해 실용성을 입증했습니다.
상세 분석
BLURR의 핵심 기술적 통찰은 모델의 가중치나 아키텍처를 변경하는 대신, 추론 파이프라인 자체를 재구성하여 계산 효율성을 극대화하는 데 있습니다. 주요 최적화 기법은 세 가지로 구분됩니다. 첫째, ‘단일 스텝 제어와 프리픽스 KV 캐싱’은 에피소드 시작 시 언어 명령어를 한 번만 처리하여 키-값(KV) 캐시를 생성하고, 이후 각 제어 스텝에서는 새롭게 들어오는 시각 및 상태 토큰만 계산하여 병합합니다. 이를 통해 매 스텝마다 반복되는 고정된 명령어 처리의 계산 낭비를 제거합니다. 둘째, ‘BF16 디코더와 컴파일, FlashAttention’은 디코더 연산을 BF16 정밀도로 실행하여 메모리 대역폭 요구량을 절반으로 줄이고, torch.compile을 통해 파이썬 오버헤드를 제거하며 커널을 융합합니다. 또한 메모리 I/O를 최적화하는 FlashAttention 커널을 적용하여 어텐션 계산 효율을 높입니다. 셋째, ‘단일 스텝 롤아웃 스케줄’은 기존 10스텝의 롤아웃 예측을 1스텝으로 축소하여 지연 시간을 근본적으로 줄입니다. 이는 단기 테이블탑 조작 작업에서 다단계 예측이 불필요하게 과도한 계산을 유발한다는 관찰에 기반합니다.
이러한 최적화는 모델의 정확성에는 거의 영향을 미치지 않으면서 하드웨어 활용도를 극적으로改善합니다. 실험 결과, BLURR는 동일한 Pi-0 체크포인트를 사용하는 기준 모델 대비 약 9.5배 낮은 지연 시간(17.1ms), 0.53배의 VRAM 사용량(7.2GB), 그리고 9.2배 높은 유효 GFLOPS를 달성했습니다. 이는 아키텍처 재설계나 재학습 없이도 추론 스택 최적화만으로 VLA 모델의 실시간 적용 가능성을 크게 높일 수 있음을 보여줍니다. 또한 사용자가 BF16, 컴파일, 제어 스텝 수 등 추론 옵션을 실시간으로 전환하며 성능-정확도 트레이드오프를 직접 관찰할 수 있는 웹 데모는 연구의 실용적 가치와 접근성을 강조합니다.
댓글 및 학술 토론
Loading comments...
의견 남기기