파라랙스 이기종 엣지 시스템에서 연산 폴백의 런타임 병렬화
초록
파라랙스는 모바일 디바이스에서 동적 제어 흐름과 지원되지 않는 연산이 CPU로 폴백될 때 발생하는 병목을 해소한다. 계산 DAG를 자동으로 분할하고, 분기 인식 메모리 풀과 버퍼 재사용 전략을 적용해 메모리 사용량을 억제한다. 적응형 스케줄러가 메모리 제한을 고려해 GPU와 CPU에 작업을 동시 배치함으로써 평균 46 %의 지연 감소와 30 % 수준의 에너지 절감을 달성한다.
상세 분석
파라랙스는 모바일 엣지 디바이스에서 DNN 추론 시 발생하는 두 가지 핵심 문제를 해결한다. 첫째, 동적 제어 흐름(조건문, 루프 등)이나 프레임워크가 지원하지 않는 연산이 발생하면 기존 시스템은 해당 연산을 CPU에 일괄적으로 넘겨버리며, 이때 CPU 코어는 대부분 유휴 상태에 머무른다. 둘째, 폴백 연산이 메모리 풀에 새 버퍼를 할당하면서 메모리 사용량이 급증하고, 이는 모바일 환경에서 심각한 스로틀링을 초래한다.
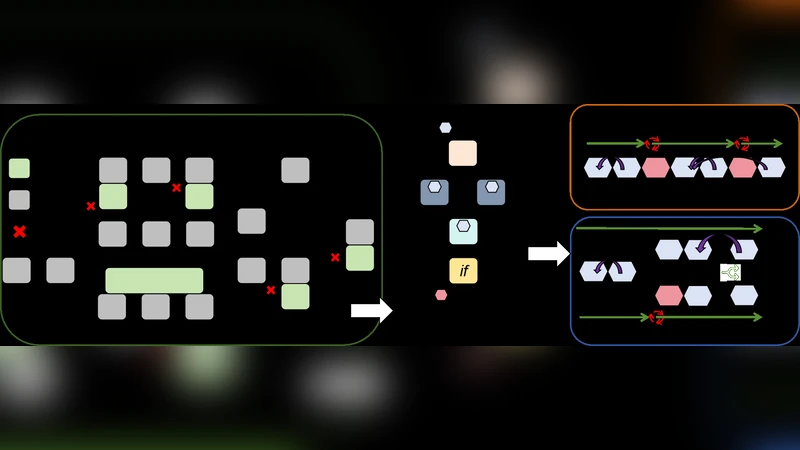
파라랙스는 이러한 문제를 ‘연산 DAG 분할 + 분기 인식 메모리 관리 + 적응형 스케줄링’이라는 삼중 구조로 접근한다. 먼저, 입력 모델의 연산 그래프를 정적 분석하여 연산 간 의존성을 보존하면서 가능한 병렬 서브그래프를 추출한다. 이때, 조건 분기 노드를 기준으로 ‘true’와 ‘false’ 경로를 별도 서브그래프로 나누어, 각 경로가 독립적으로 실행될 수 있도록 설계한다.
두 번째 단계에서는 메모리 관리 모듈이 각 서브그래프에 전용 메모리 아레나를 할당한다. 아레나는 사전에 정의된 크기의 버퍼 풀로 구성되며, 연산이 종료될 때마다 버퍼를 즉시 반환해 재사용한다. 특히, 분기 경로가 교차하는 지점에서는 공유 버퍼를 최소화하고, 필요시 복제 버퍼를 생성해 메모리 충돌을 방지한다. 이러한 ‘branch‑aware’ 전략은 메모리 파편화를 크게 감소시켜 전체 메모리 피크를 평균 26.5 % 수준으로 억제한다.
마지막으로, 적응형 스케줄러는 런타임에 디바이스의 현재 메모리 사용량과 연산 부하를 모니터링한다. 메모리 여유가 충분하면 GPU와 CPU에 동시에 서브그래프를 할당해 완전 병렬 실행을 수행하고, 메모리 제약이 걸리면 메모리 사용량이 낮은 서브그래프를 우선 실행하거나, 일부 연산을 순차적으로 전환한다. 스케줄러는 히스테리시스 기반의 정책을 사용해 급격한 스위칭을 방지하고, 에너지 효율을 최적화한다.
실험에서는 MobileNetV2, EfficientNet‑B0, YOLO‑v5 등 다섯 개의 대표적인 모델을 Snapdragon 845, MediaTek Dimensity 820, Apple A14 등 세 종류의 모바일 SoC에 적용했다. 파라랙스는 기존 TensorFlow Lite와 PyTorch Mobile 대비 평균 46 %의 지연 감소를 기록했으며, 메모리 오버헤드는 26.5 % 수준에 머물렀다. 에너지 측정에서는 GPU 활용도가 30 % 이상 증가하면서 전체 전력 소모가 최대 30 % 절감되었다.
핵심 인사이트는 ‘동적 연산을 정적 DAG 분할과 런타임 메모리 관리가 결합될 때, 이기종 코어를 효율적으로 활용할 수 있다’는 점이다. 파라랙스는 모델 리팩터링 없이도 기존 프레임워크와 호환되며, 새로운 연산을 추가로 구현할 필요가 없다는 실용적 장점을 제공한다.