실시간 스트리밍을 위한 초고속 초상화 애니메이션 프레임워크 PersonaLive
초록
PersonaLive는 하이브리드 암시적 모션 신호와 3D 암시적 키포인트를 이용해 정교한 얼굴 움직임을 제어하고, 단계별 외관 디스틸레이션으로 샘플링 단계를 크게 줄여 실시간 스트리밍에 적합한 초고속 초상화 애니메이션을 구현한다. 마이크로‑청크 자동회귀 생성 방식과 슬라이딩 학습·히스토리 키프레임 메커니즘을 도입해 낮은 지연시간과 장기적인 시간 일관성을 동시에 달성한다.
상세 분석
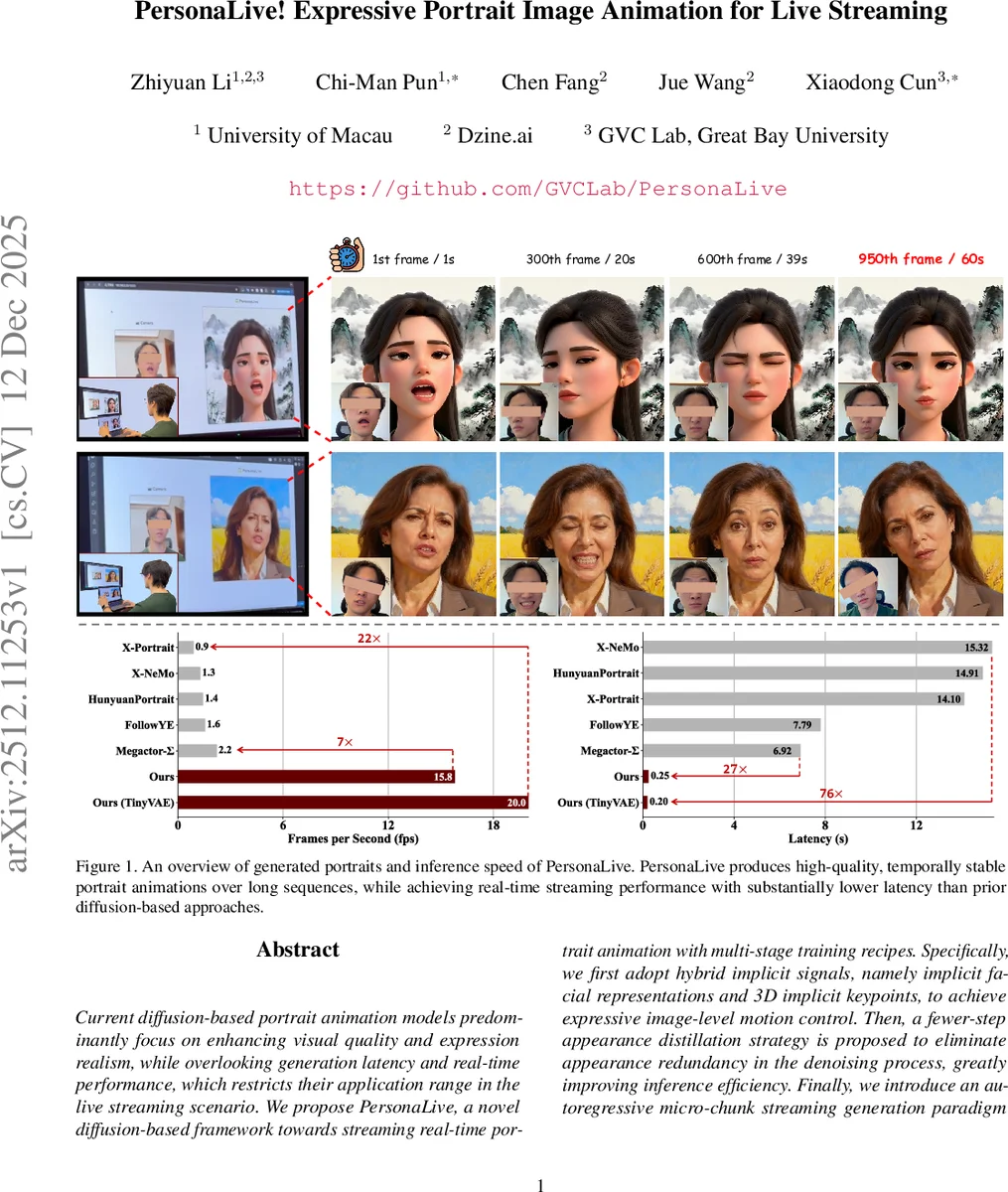
본 논문은 기존 diffusion 기반 초상화 애니메이션 모델이 시각 품질과 표현 현실성에 집중하면서도 실시간 스트리밍에 필요한 지연시간과 연산 효율성을 간과한 점을 정확히 지적한다. 이를 해결하기 위해 세 가지 핵심 기술을 제안한다. 첫째, ‘Hybrid Implicit Signals’로 명명된 모션 제어 방식은 2D 랜드마크 대신 3D 암시적 키포인트와 얼굴 임베딩을 결합한다. 3D 키포인트는 회전·이동·스케일을 포함한 전역적인 머리 움직임을 자연스럽게 표현하고, 얼굴 임베딩은 미세한 표정 변화를 캡처한다. 두 신호는 각각 Cross‑Attention과 PoseGuider를 통해 Diffusion UNet에 주입되며, 이는 기존 ControlNet 기반 접근법보다 파라미터 효율성과 제어 정밀도가 높다. 둘째, ‘Fewer‑Step Appearance Distillation’은 초기 몇 단계에서 구조와 움직임을 확정하고, 이후 단계에서 발생하는 외관 세부 조정의 중복성을 제거한다. 저자는 전체 denoising 과정을 N 단계로 압축하고, 무작위 샘플링된 중간 단계에 대해 최종 단계만 역전파함으로써 메모리 사용량을 크게 낮추면서도 모든 타임스텝에 대한 학습 신호를 확보한다. 손실 함수는 L2, LPIPS, 그리고 GAN 기반 adversarial loss를 가중합한 복합 형태로, 텍스처와 조명 디테일을 유지한다. 셋째, ‘Micro‑Chunk Streaming Generation’은 기존 고정‑길이 청크 방식의 한계를 넘어, 프레임을 미세 청크 단위로 나누어 점진적으로 노이즈 레벨을 상승시킨다. 각 청크는 독립적인 denoising 윈도우를 갖고, 윈도우가 슬라이드될 때마다 새로운 노이즈 청크가 추가된다. 이 구조는 연속적인 프레임 생성 시 중복 연산을 없애고, 실시간 스트리밍에 필수적인 낮은 레이턴시를 보장한다. 그러나 자동회귀 방식은 exposure bias와 장기 오류 누적 문제를 야기할 수 있다. 이를 완화하기 위해 ‘Sliding Training Strategy’와 ‘Historical Keyframe Mechanism’를 도입한다. 슬라이딩 학습은 훈련 시에도 스트리밍 프로세스를 시뮬레이션해 모델이 자체 예측 오류에 익숙해지게 하고, 히스토리 키프레임은 과거 안정된 프레임을 보조 조건으로 활용해 시간적 일관성을 강화한다. 실험 결과, PersonaLive는 기존 diffusion 기반 모델 대비 7배에서 22배까지 추론 속도가 향상되었으며, 정량적 지표(FID, LPIPS)와 정성적 시각 품질 모두에서 최첨단 수준을 기록한다. 특히 장시간(수백 프레임) 영상에서도 오류 누적이 최소화되어, 실시간 방송 환경에 바로 적용 가능한 수준의 품질‑속도 트레이드오프를 달성한다.
댓글 및 학술 토론
Loading comments...
의견 남기기