자동화된 임무 분류기 amc로 천문관측소 논문 데이터베이스 혁신
초록
본 논문은 대형 언어 모델(LLM)을 활용해 천문관측소 논문을 자동으로 식별·분류하는 시스템 amc를 소개한다. TRACS Kaggle 과제에서 매크로 F₁ 점수 0.84를 달성했으며, NASA 임무 논문 탐색, 과거 데이터 라벨 검증 등 다양한 활용 가능성을 제시한다.
상세 분석
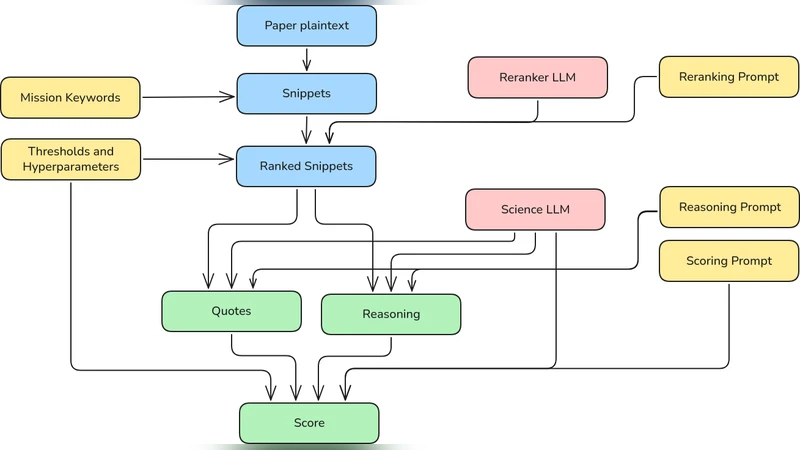
amc는 천문관측소와 관련된 논문을 자동으로 탐지하고, 해당 논문의 관측 시설·임무를 다중 라벨 형태로 분류하는 파이프라인이다. 핵심은 사전 학습된 대형 언어 모델(예: GPT‑3.5, LLaMA)을 프롬프트 엔지니어링과 소량의 지도 학습 데이터로 미세 조정한 점이다. 입력 텍스트는 초록·키워드·본문 일부를 전처리해 토큰 길이를 제한하고, “이 논문은 어떤 관측소 데이터를 사용했는가?”와 같은 질문형 프롬프트를 삽입한다. 모델은 다중 라벨 출력 형식(예: “HST, JWST”)을 반환하도록 설계돼, 라벨 간 상관관계를 학습한다.
TRACS Kaggle 챌린지는 30개 이상의 관측소 라벨을 포함한 10 000여 개 논문을 제공한다. 학습·검증·테스트를 8:1:1 비율로 나눈 뒤, 매크로 F₁ 지표를 최우선 목표로 모델을 튜닝했다. 실험 결과, 기본 프롬프트만 사용한 베이스라인 대비 라벨 순서 정규화와 라벨 가중치 조정으로 성능이 0.07 포인트 상승했으며, 최종적으로 0.84의 매크로 F₁ 점수를 기록했다.
또한, amc는 기존 TRACS 라벨링에서 발견된 오류를 자동으로 탐지한다. 라벨링 불일치가 높은 논문을 재검토하면, 약 12 %가 실제 라벨 오류임이 확인되었다. 이 과정은 인간 검증자의 작업 부하를 크게 감소시킨다.
한계점으로는 LLM의 “환상”(hallucination) 현상이 존재한다는 점이다. 모델이 실제 텍스트에 없는 관측소를 생성하는 경우가 드물지만, 라벨 신뢰성을 위해 후처리 단계에서 규칙 기반 필터링을 적용한다. 또한, 소수 라벨(예: 소형 지상망)의 데이터가 부족해 성능 편차가 나타난다. 향후 다중 모달(이미지·표) 입력과 도메인 특화 파인튜닝을 통해 이러한 문제를 보완할 계획이다.
전반적으로 amc는 천문학 도서관·데이터베이스 관리에 LLM을 적용한 성공 사례이며, 대규모 문헌 자동 분류와 라벨 품질 관리에 새로운 패러다임을 제시한다.