iouring 으로 DBMS 성능 극대화
초록
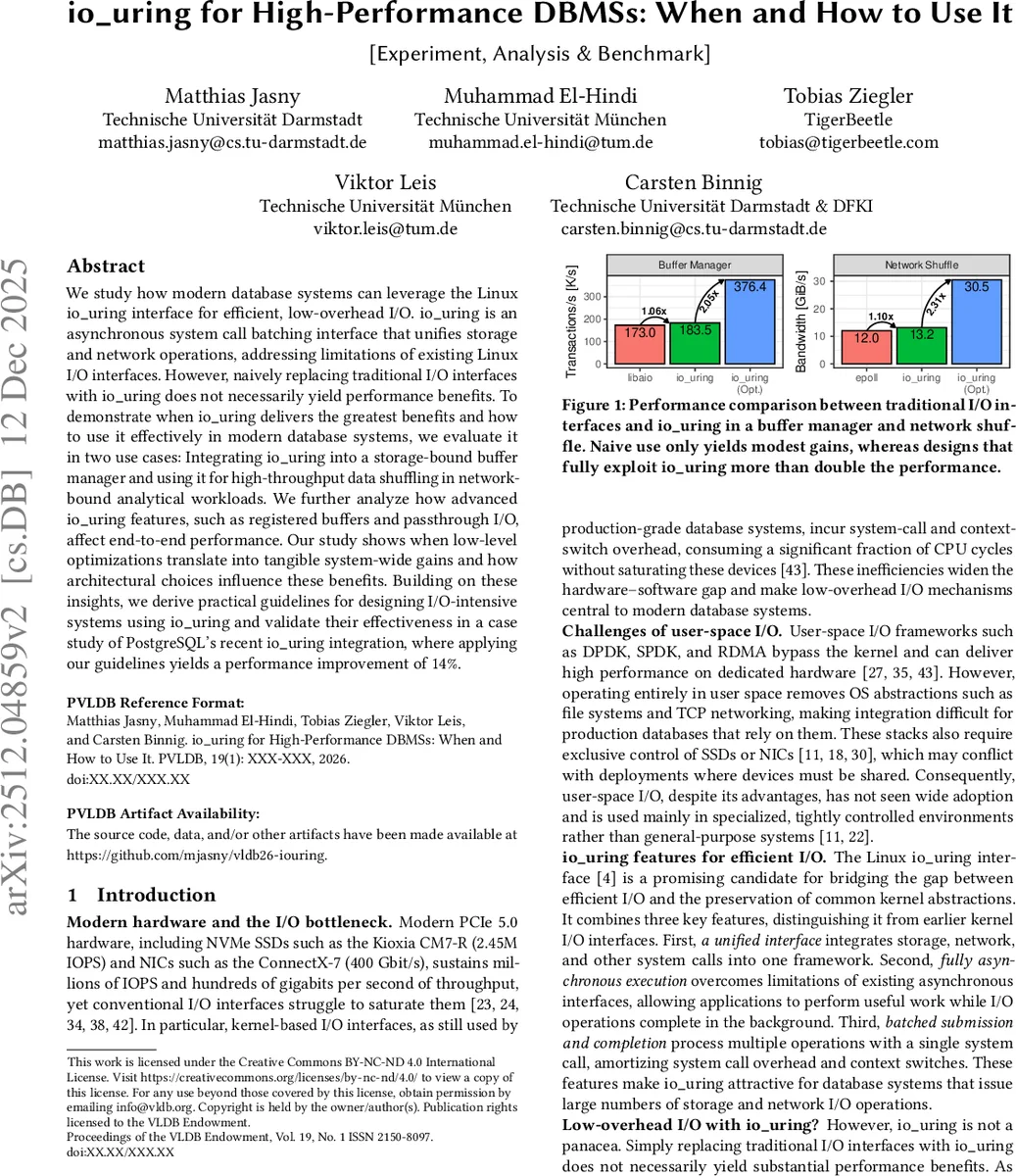
본 논문은 Linux io_uring 인터페이스를 데이터베이스 시스템에 적용했을 때 얻을 수 있는 성능 향상의 조건과 최적 활용 방법을 제시한다. 저장‑중심 버퍼 매니저와 네트워크‑중심 데이터 셔플링 두 가지 워크로드를 실험으로 분석하고, 등록 버퍼·패스스루 I/O 등 고급 기능의 효과를 정량화한다. 연구 결과, 단순 교체만으로는 미미한 개선에 그치지만, 배치와 버퍼 등록을 포함한 설계 최적화를 적용하면 전체 처리량이 2배 이상 증가한다. 파생된 가이드라인을 PostgreSQL에 적용해 14 %의 추가 성능 향상을 달성하였다.
상세 분석
논문은 io_uring이 제공하는 세 가지 핵심 특성—통합 I/O 인터페이스, 완전 비동기 실행, 그리고 시스템 콜 배치—을 DBMS 설계에 어떻게 매핑할 수 있는지를 상세히 탐구한다. 먼저, 기존의 read/write·epoll·libaio 조합이 시스템 콜·컨텍스트 스위치 비용으로 I/O 파이프라인을 병목화한다는 점을 지적한다. io_uring은 SQ와 CQ라는 공유 메모리 링을 통해 사용자와 커널 간 데이터 복사를 없애고, 한 번의 io_uring_enter 호출로 다수의 I/O를 제출·완료함으로써 오버헤드를 5~6배 감소시킨다. 그러나 이러한 이점은 배치 크기와 실행 경로 선택에 크게 좌우된다. 배치가 너무 작으면 오버헤드 절감 효과가 미미하고, 과도한 배치는 지연시간을 늘려 트랜잭션 응답성을 해칠 수 있다. 또한, 기본 인라인·비동기·워커 스레드 세 가지 실행 경로 중 워커 스레드로 강제 전환(IOSQE_ASYNC) 시 7 µs 수준의 추가 지연이 발생한다는 마이크로벤치마크 결과는, DBMS가 블로킹 호출을 최소화하고 가능한 한 인라인·비동기 경로를 활용해야 함을 시사한다.
버퍼 등록(registration)과 고정(pin) 기능은 메모리 복사와 페이지 폴트 비용을 크게 낮춘다. 특히, 대용량 NVMe SSD에서 페이지 단위 읽기·쓰기 작업을 수행할 때, 사전 등록된 버퍼를 사용하면 페이지 복사 단계가 사라져 CPU 사이클당 IOPS가 두 배 이상 상승한다. 패스스루 I/O(passthrough)와 멀티샷(multishot) 기능은 네트워크 셔플링 시 연속적인 소켓 읽기/쓰기 작업을 한 번의 요청으로 묶어 처리하게 해, 400 Gbps 네트워크에서 전송 지연을 30 % 이상 감소시킨다.
실제 적용 사례로, 저자들은 버퍼 매니저와 셔플 엔진에 각각 io_uring을 통합하고, SQPoll 모드, DEFER_TASKRUN 플래그, 적절한 배치 크기(16~64) 등을 조정했다. 그 결과 저장‑중심 워크로드에서는 처리량이 2.05배, 네트워크‑중심 워크로드에서는 2.31배 향상되었다. 마지막으로 이러한 설계 원칙을 PostgreSQL의 최신 io_uring 백엔드에 적용했을 때, 기존 io_uring 사용 대비 14 % 추가 속도 개선을 달성했다.
이 연구는 io_uring이 단순 교체만으로는 효과가 제한적이며, DBMS 아키텍처 전반에 걸친 배치 설계, 버퍼 관리, 실행 경로 최적화가 필수임을 강조한다. 또한, 고성능 SSD·NIC 환경에서 io_uring을 활용하려면 워크로드 특성(IOPS‑집중 vs. 대역폭‑집중), 시스템 콜 빈도, 메모리 레이아웃을 종합적으로 고려한 튜닝이 필요함을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기