대형 언어 모델의 자신감 함정: 과신, 교정, 그리고 방해 요소의 효과
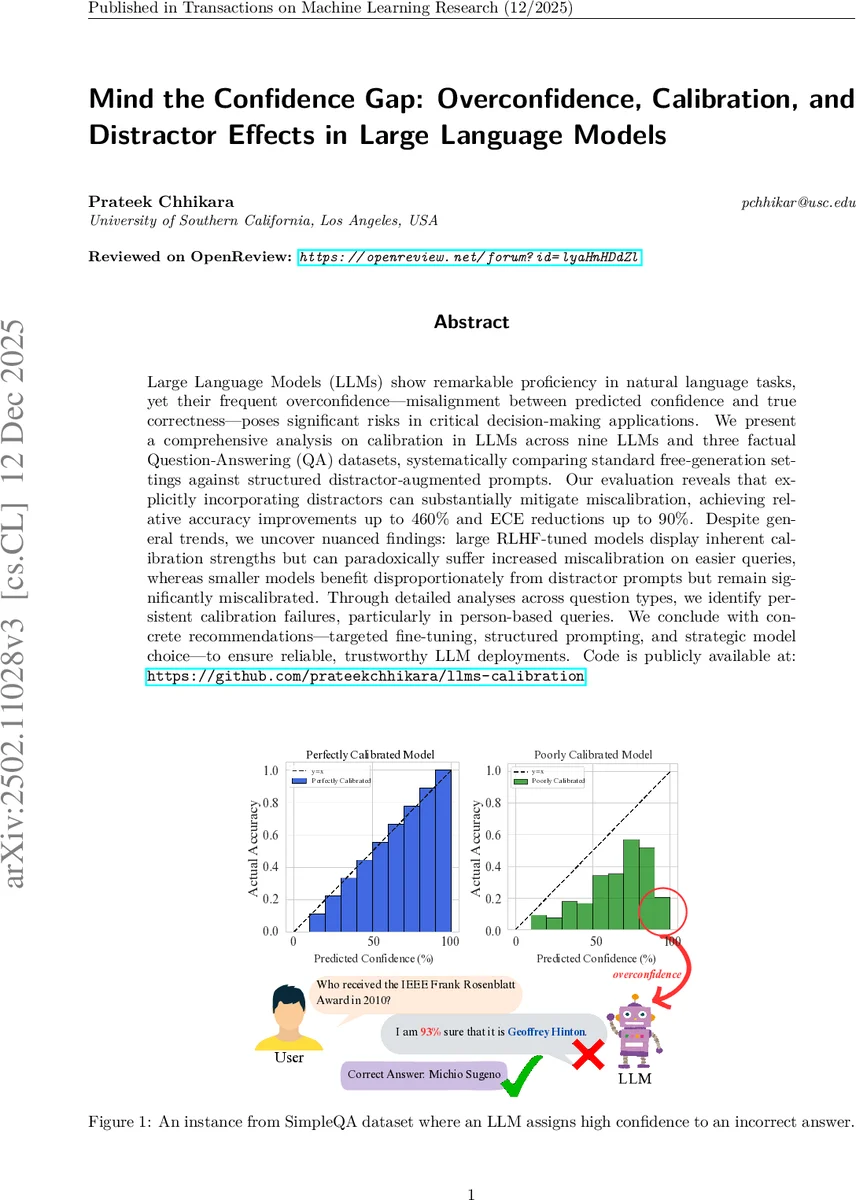
초록
본 연구는 LLM의 예측 신뢰도와 실제 정확도 간 불일치인 ‘과신’ 문제를 분석합니다. 9개 LLM과 3개 QA 데이터셋을 활용한 실험 결과, 명시적 방해 요소를 제시하는 구조화된 프롬프트가 모델의 교정(calibration)을 크게 개선하며, 정확도는 최대 460%, 교정 오류(ECE)는 최대 90% 개선될 수 있음을 발견했습니다. 특히 대형 RLHF 모델은 쉬운 질문에서 오히려 교정이 악화되는 역설을, 소형 모델은 방해 요소에 큰 이득을 보이지만 여전히 높은 오류를 보이는 등 복잡한 양상을 확인했습니다.
상세 분석
본 논문의 기술적 분석과 핵심 통찰은 다음과 같습니다.
실험 설계의 혁신성: 기존 연구가 주로 사후 교정 방법(온도 조정 등)에 집중했다면, 본 연구는 ‘방해 요소 증강 평가 패러다임’이라는 새로운 접근법을 제시했습니다. 이는 실제 QA 시스템(예: 검색 기반 생성, 객관식)에서 흔히 마주치는 ‘하나의 정답과 여러 개의 그럴듯한 오답’ 상황을 구조화된 프롬프트로 재현하여, 모델의 교정 행위를 보다 현실적으로 평가할 수 있게 합니다.
핵심 발견점:
- 방해 요소의 강력한 효과: 모든 모델에서 방해 요소 설정(D)이 자유 생성 설정(N) 대비 정확도와 ECE를 극적으로 개선했습니다. 이는 인간의 인지적 ‘반대 고려하기(consider-the-opposite)’ 전략이 LLM의 과신 완화에도 유효함을 시사합니다.
- 모델 규모와 조정 방식의 복잡한 상호작용:
- 대형 RLHF 모델의 역설: GPT-4o, LLaMA-3-70B 등 대형 RLHF 모델은 전반적으로 우수한 교정 성능을 보였으나, 쉬운 질문(TriviaQA)에서 방해 요소 도입 시 오히려 ECE가 증가하는 현상을 보였습니다. 이는 고도로 정렬된 모델이 명시적인 선택지가 주어지면 지나치게 확신하는 경향이 있음을 의미할 수 있습니다.
- 소형 모델의 불균형 이득: LLaMA-3-8B, Gemma2-9B 등 소형 모델은 방해 요소 설정에서 정확도가 절대적으로 크게 상승했으나, 여전히 상대적으로 높은 ECE를 유지했습니다. 즉, 성능은 개선되더라도 신뢰도 추정 자체의 정확성은 부족함을 보입니다.
- 질문 유형별 취약점: ‘사람(Person)’ 기반 질문에서 교정 실패가 가장 두드러졌습니다. 이는 인물 관련 지식이 모호하거나 중복될 가능성이 높아, 모델이 자신의 지식 한계를 평가하기 어렵기 때문으로 해석됩니다.
방법론적 고려사항: 연구자는 신뢰도 측정을 ‘토큰 확률’이 아닌 ‘언어화된 자기 보고(elicited self-reports)‘에 의존했습니다. 이는 블랙박스 API 모델을 포함한 모든 모델을 동일 기준으로 비교 가능하게 하며, RLHF 조정 후 토큰 확률이 교정 신호로써 분해될 수 있다는 기존 연구 결과와도 부합합니다. 그러나 이는 동시에 ‘말로 표현한 자신감’이라는 특정 측정법에 대한 발견임을 의미합니다.
시사점: 이 연구는 LLM의 신뢰성 향상을 위해 단순한 사후 보정보다는 훈련/조정 단계부터 교정을 고려한 목표 설정(Calibration-aware RLHF), 배치 시 구조화된 프롬프트 사용, 그리고 작업 난이도와 모델 규모/조정 방식을 고려한 전략적 모델 선택의 중요성을 강력히 시사합니다.
댓글 및 학술 토론
Loading comments...
의견 남기기