분산형 프라이버시 보호 인센티브 호환 데이터 마켓플레이스 D2M
초록
D2M은 블록체인 스마트 계약과 연계된 경매·에스크로·분쟁 해결 메커니즘을 통해 데이터 구매자를 연결하고, 오프체인 실행 레이어인 CONE에 학습 작업을 위임한다. 수정된 YODA 프로토콜과 Corrected OSMD를 도입해 비잔틴 노드와 저품질 기여자를 견제하며, 모든 절차가 게임 이론적으로 인센티브 호환성을 갖는다. 이 시스템을 이더리움에 구현해 MNIST·Fashion‑MNIST·CIFAR‑10 실험에서 높은 정확도와 30 % 이하 비잔틴 공격에 대한 강인성을 입증하였다.
상세 분석
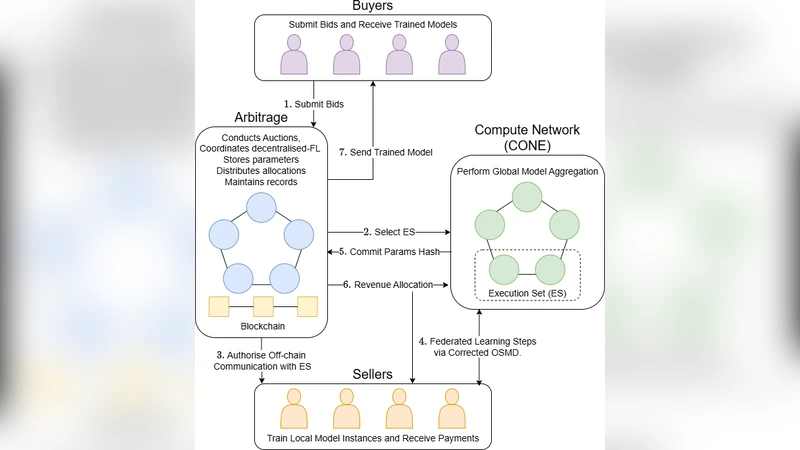
본 논문은 협업 학습 환경에서 데이터 제공자와 소비자 간의 신뢰·프라이버시·인센티브 문제를 하나의 통합 프레임워크로 해결하려는 시도이다. 먼저 데이터 구매자는 블록체인 스마트 계약을 통해 입찰 기반 요청을 제출하고, 계약은 자동으로 경매를 진행해 최적의 데이터 제공자를 선정한다. 이때 에스크로 메커니즘이 적용돼 거래 금액이 사전에 잠금되며, 결과에 대한 분쟁이 발생하면 계약 내 정의된 절차에 따라 중재가 이루어진다. 이러한 설계는 탈중앙화된 신뢰 기반을 제공하면서도 기존 중앙 집중형 데이터 마켓플레이스가 갖는 단일 장애점을 제거한다.
학습 자체는 CONE(Compute Network for Execution)이라는 오프체인 분산 실행 레이어에 위임된다. CONE는 블록체인과 별도로 고성능 GPU/TPU 자원을 풀링해 대규모 모델 학습을 가능하게 하며, 결과 해시만을 체인에 기록해 검증 가능성을 유지한다. 여기서 핵심은 수정된 YODA 프로토콜이다. 원래 YODA는 무작위 샘플링을 통해 실행자를 선택했지만, 논문은 실행 집합을 지수적으로 확대해 점진적으로 더 많은 노드가 결과에 참여하도록 설계했다. 이 방식은 악의적 실행자가 초기 단계에서 결과를 조작하더라도, 이후 확대된 집합에서 다수결에 의해 교정될 확률을 크게 높인다.
또한 데이터 제공자의 기여 품질을 평가하기 위해 Corrected OSMD(Online Stochastic Mirror Descent) 알고리즘을 변형하였다. 기존 OSMD는 손실 함수 기반으로 기여자를 순위화하지만, 악의적 혹은 저품질 데이터가 포함될 경우 수렴 속도가 급격히 저하된다. 논문은 손실에 대한 가중치를 동적으로 조정하고, 비정상적인 기여를 탐지하면 해당 제공자를 페널티(보증금 차감)와 함께 제외시킨다. 이 과정은 게임 이론적 분석을 통해 모든 참여자가 정직하게 행동할 때 기대 보상이 최대가 되도록 설계되었으며, 따라서 인센티브 호환성을 만족한다.
보안 분석에서는 데이터 프라이버시 보호를 위해 학습 과정에서 원시 데이터를 노출하지 않는 연합 학습 방식을 차용했으며, 실행 결과는 해시 형태로만 체인에 기록돼 데이터 유출 위험을 최소화한다. 비잔틴 노드 비율이 30 %까지 상승해도 정확도 저하가 3 % 이하에 머무르는 실험 결과는 제안된 합의 메커니즘과 품질 보정이 실제 공격 상황에서도 견고함을 입증한다. 다만 CIFAR‑10과 같은 복잡한 데이터셋에서는 정확도가 56 %에 그쳐, 고차원 모델 학습 시 오프체인 실행 비용과 품질 보정 오버헤드가 여전히 한계점으로 남는다.
전체적으로 D2M은 블록체인 기반 거래·합의·인센티브 설계와 오프체인 고성능 학습을 효과적으로 결합했으며, 기존 연합 학습·블록체인 마켓플레이스의 단점을 보완한다. 그러나 실행 레이어의 스케일링 비용, 스마트 계약 가스 비용, 그리고 복잡한 모델에 대한 정확도 한계는 향후 연구가 필요한 부분이다.