다차원 선호 정렬을 위한 보상 조건화
초록
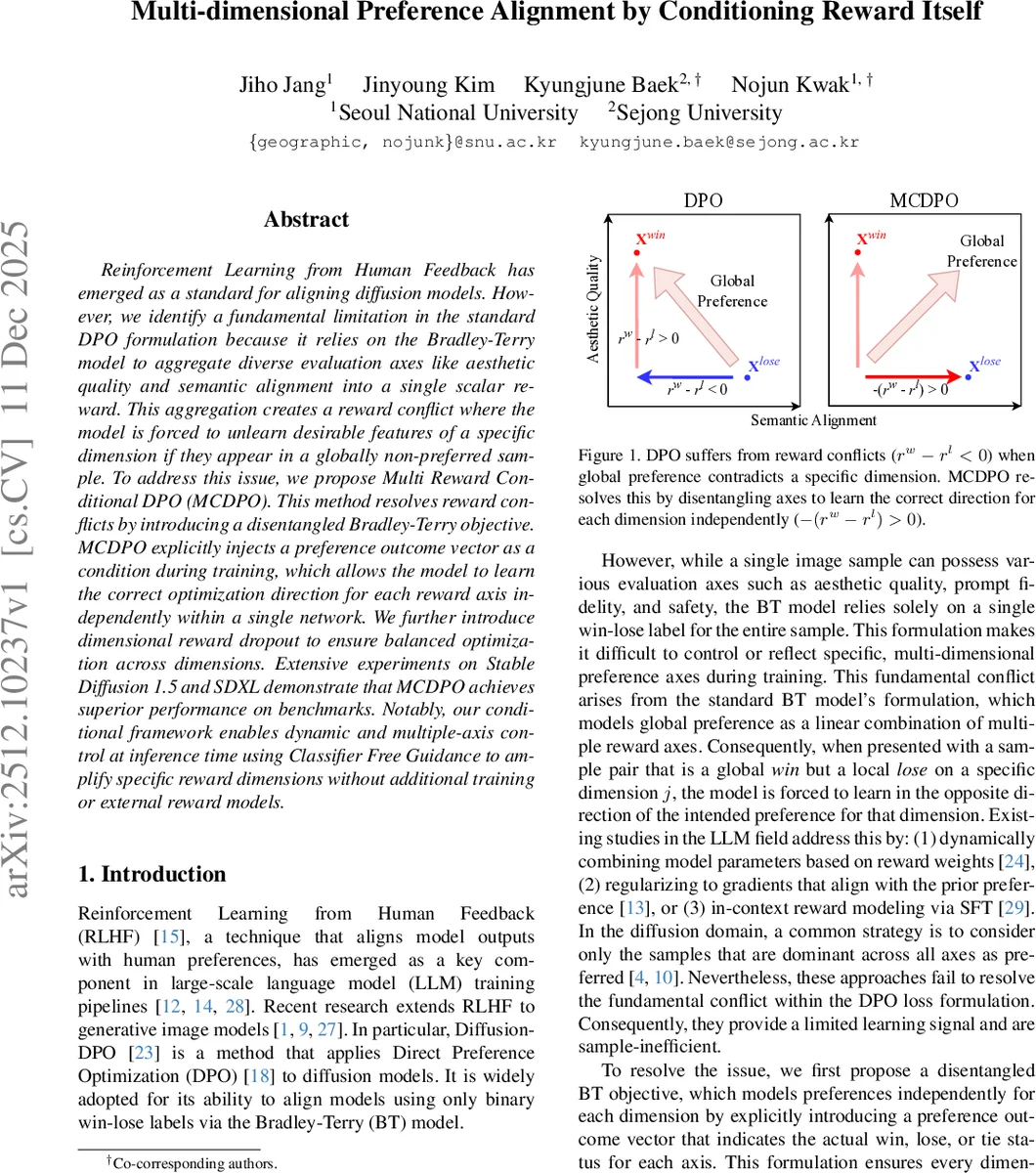
본 논문은 기존 DPO가 다중 평가 축을 하나의 스칼라 보상으로 압축하면서 발생하는 “보상 충돌” 문제를 지적하고, 보상 결과 벡터를 조건으로 삽입하는 Multi‑Reward Conditional DPO(MCDPO)를 제안한다. MCDPO는 각 축을 독립적으로 학습하도록 설계돼, 학습 효율과 샘플 품질을 동시에 향상시키며, 추론 단계에서 CFG와 결합해 축별 가중치를 동적으로 조절할 수 있다.
상세 분석
DPO는 Bradley‑Terry(BT) 모델을 이용해 쌍별 선호를 스칼라 보상 r(x,c)=∑_i w_i r_i(x,c) 로 변환한다. 이때 서로 다른 축(예: 미학, 의미 정렬, 안전성)에서 상반된 결과가 존재하면, 전역적으로 “승리”인 샘플이라도 특정 축에서는 “패배”가 될 수 있다. 기존 손실 L_DPO는 전역 승패에만 초점을 맞추므로, 해당 축에 대한 그래디언트가 반대 방향으로 흐르게 되어 보상 충돌이 발생한다. 논문은 이를 수학적으로 분석하고, 각 축별 승·패·동점 정보를 담은 벡터 γ∈ℝ^D 를 도입한 “분리된 BT” 모델 p⊥_BT(x_w>x_l|c,γ)=σ(∑_i w_i γ_i (r_i(x_w)-r_i(x_l))) 를 제안한다. γ_i가 -1이면 해당 축의 신호가 뒤집혀, 모든 축이 올바른 방향으로 최적화된다.
하지만 D개의 별도 모델을 학습하는 것은 계산량이 비현실적이다. 저자는 γ를 조건으로 받아들이는 단일 확산 모델 p(x|c,γ)를 설계해, 하나의 네트워크가 D개의 암묵적 보상 함수를 동시에 학습하도록 만든다. 구체적으로 r_θ(x,c,γ)=β·log(p(x|c,γ)/p_ref(x|c)) 로 정의하고, 양쪽 쌍 방향을 모두 이용한 손실 L_MC = -E
댓글 및 학술 토론
Loading comments...
의견 남기기