SMILES 문자열로 예측하는 고분자 용해도
초록
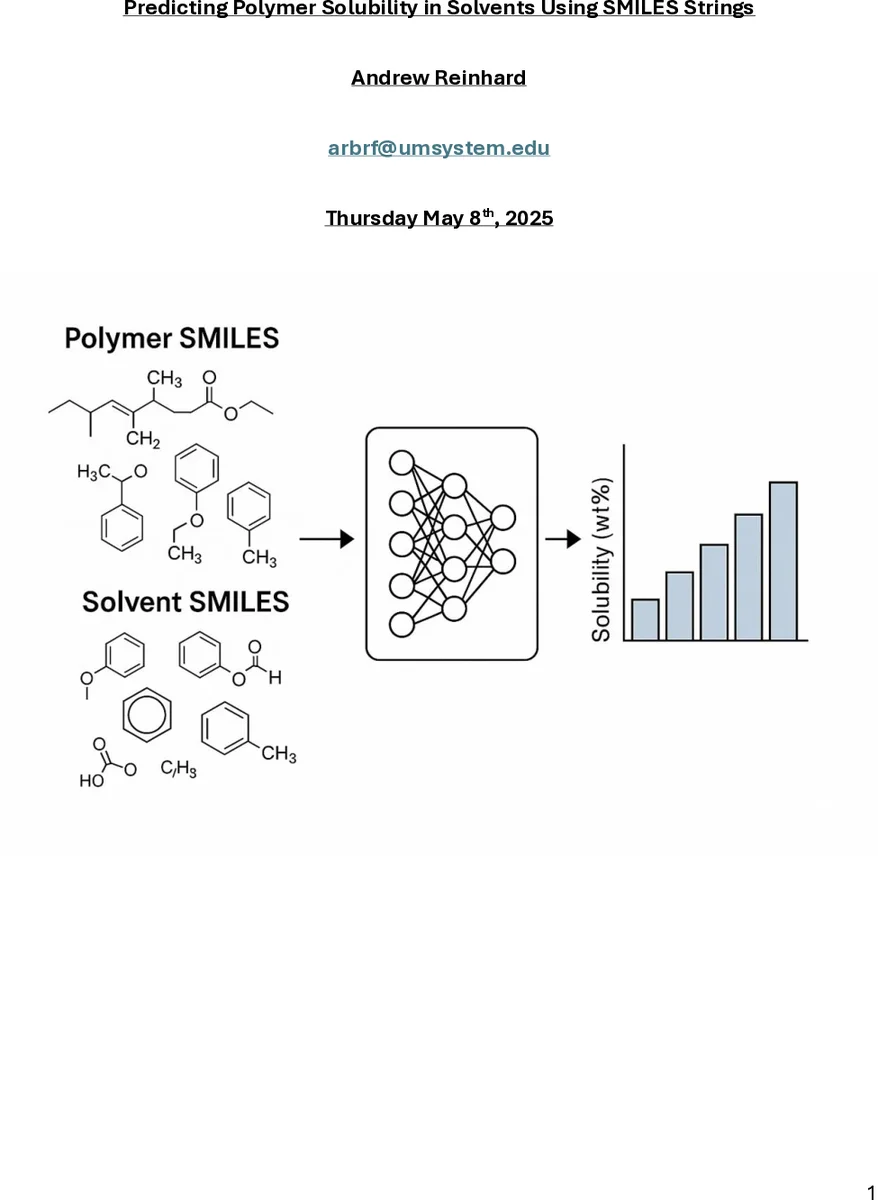
본 연구는 고분자와 용매의 SMILES 문자열만을 입력으로 사용하여 고분자의 용해도(중량%)를 예측하는 딥러닝 모델을 제시합니다. 8,049개의 고분자-용매 쌍 데이터를 바탕으로 분자 서술자와 지문을 결합한 2,394차원 특징 벡터를 생성하고, 6개의 은닉층을 가진 신경망을 학습시켰습니다. 모델은 검증 데이터에서 높은 정확도(R²=0.8076)를 보였으며, 실험 데이터로 외부 검증 시에도 강력한 일반화 성능(R²=0.7648)을 입증하여 고속 용매 스크리닝 및 친환경 설계에의 활용 가능성을 제시합니다.
상세 분석
이 연구는 고분자 공학과 기계학습의 접점에서 의미 있는 진전을 보여줍니다. 핵심 기술적 기여는 SMILES 문자열이라는 단순한 입력으로부터 분자 서술자(분자량, logP, TPSA 등 6종)와 두 종류의 화학 지문(1024비트 Morgan, 167비트 MACCS)을 추출하여 고차원(2394차원) 특징 벡터를 구성한 점입니다. 이는 구조적, 물리화학적 정보를 포괄적으로 담아내며, 특히 MACCS 지문의 사용은 기능기 반응성을 간접적으로 반영할 수 있어 용해도 예측에 유리했을 것으로 분석됩니다.
모델 아키텍처는 6개의 완전 연결 은닉층을 가진 심층 신경망(DNN)으로, 배치 정규화와 드롭아웃(0.2)을 적용해 과적합을 방지했습니다. 기준 모델인 랜덤 포레스트(R²=0.4433)에 비해 DNN의 성능(R²=0.8076)이 월등히 높은 것은 고분자-용매 상호작용의 복잡한 비선형성을 학습하는 데 심층 신경망의 표현력이 필수적임을 시사합니다. 더욱 주목할 점은 훈련 데이터가 분자동역학 시뮬레이션으로부터 생성된 ‘계산 데이터’임에도 불구, 실험 데이터(Materials Genome Project)에 대한 외부 검증에서도 높은 정확도(R²=0.7648)를 유지했다는 것입니다. 이는 시뮬레이션 데이터의 품질이 우수했음을 반증하며, 계산 데이터로 사전 학습된 모델이 실험 영역으로의 전이 학습에 유용할 수 있는 가능성을 열어줍니다.
한계점으로는, 연구에 사용된 고분자가 8종으로 산업적 중요성은 높으나 화학적 다양성이 제한적이며, 상온(25°C) 조건에만 국한되었다는 점이 지적됩니다. 또한 이진 분류(양호 용매/비용매) 성능은 검증되었으나, 외부 실험 데이터셋에 비용매 케이스가 없어 해당 분류 성능의 실제 적용 가능성은 추가 검증이 필요합니다. 전반적으로, 이 연구는 전통적인 실험 및 시뮬레이션 방법을 보완하는 빠르고 확장 가능한 AI 기반 예측 도구의 실용성을 입증한 중요한 사례입니다.
댓글 및 학술 토론
Loading comments...
의견 남기기