글레이셔 호수 분할과 위치 추론을 위한 대형 언어 모델 기반 프레임워크 GLACIA
초록
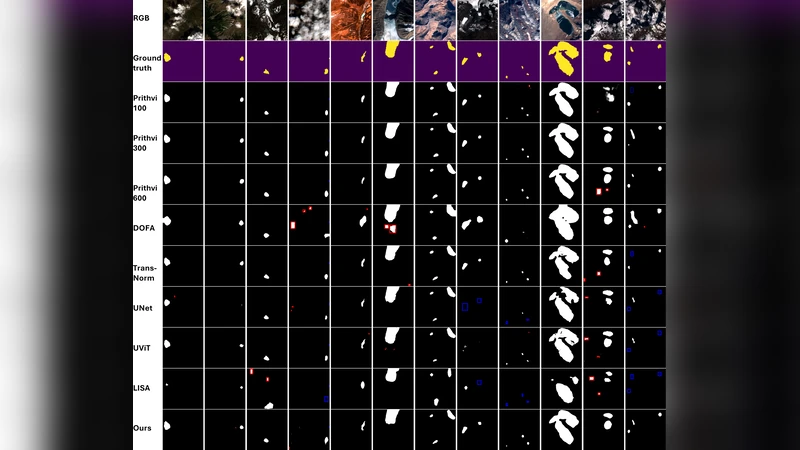
GLACIA는 대형 언어 모델(LLM)과 이미지 분할 네트워크를 결합해 빙하 호수의 픽셀 마스크와 동시에 인간이 이해 가능한 위치 추론 문장을 생성한다. 새로 구축한 GLake‑Pos 데이터셋은 인스턴스‑레벨의 공간 질문‑답쌍을 제공하며, 이를 통해 모델은 전통적인 CNN·ViT 기반 방법보다 높은 mIoU(87.30)를 달성한다. 자연어 인터페이스를 통한 직관적인 재해 대비와 정책 결정 지원이 가능하다.
상세 분석
GLACIA는 기존 원격탐사 분야에서 흔히 볼 수 있는 픽셀‑레벨 분할만을 수행하는 CNN·ViT 기반 접근법과 달리, 고차원 의미와 인간 친화적 설명을 동시에 제공한다는 점에서 혁신적이다. 핵심 설계는 두 단계로 나뉜다. 첫 번째 단계에서는 멀티스케일 CNN‑ViT 하이브리드 백본을 이용해 고해상도 특징 맵을 추출하고, 이를 토큰화하여 LLM 입력 형태로 변환한다. 여기서 사용된 토크나이저는 공간 좌표와 객체 인스턴스 정보를 보존하도록 설계돼, LLM이 “북쪽에 위치한 호수 A의 면적은?”과 같은 질문에 정확히 대응할 수 있다. 두 번째 단계에서는 사전 학습된 대형 언어 모델(예: LLaMA‑2) 위에 가벼운 어댑터 레이어를 추가해 시각 토큰과 언어 토큰을 교차 정렬한다. 이 과정에서 교차‑어텐션 메커니즘이 시각 특징과 텍스트 프롬프트를 동시에 고려해, 분할 마스크와 자연어 설명을 공동으로 출력한다.
데이터 측면에서 저자들은 GLake‑Pos 파이프라인을 구축해, 위성 영상에 존재하는 각 빙하 호수를 자동으로 인스턴스화하고, 위치 관계(예: “호수 B는 호수 A의 동쪽에 있다”)와 정량적 속성(면적, 깊이 등)을 포함한 12만 개 이상의 QA 쌍을 생성했다. 이는 기존 원격탐사 데이터셋이 갖는 “라벨만 존재하고 설명이 없는” 한계를 극복한다.
성능 평가에서는 mIoU, mAcc, 그리고 자연어 추론 정확도(Exact Match) 세 가지 지표를 사용했다. GLACIA는 mIoU 87.30으로 CNN 기반(78.5579.01), ViT 기반(69.2781.75), 지오‑기반 모델(76.37~87.10)보다 전반적으로 우수했으며, 특히 복잡한 인스턴스 겹침 상황에서 기존 방법이 혼동하는 부분을 정확히 구분했다. 언어 추론 측면에서도 84.2%의 Exact Match를 기록, 질문에 대한 일관된 답변을 제공한다.
한계점으로는 LLM의 파라미터 규모가 크기 때문에 추론 비용이 높고, 고해상도 위성 영상 전체를 처리하려면 메모리 최적화가 필요하다는 점을 들 수 있다. 또한, GLake‑Pos는 자동 생성 과정에서 일부 오류(잘못된 인스턴스 라벨링)를 포함하고 있어, 인간 검증 단계가 추가로 요구된다. 향후 연구에서는 경량화된 멀티모달 어댑터 개발, 실시간 재해 모니터링 파이프라인 연계, 그리고 다른 지형(예: 산사태, 홍수 지역)으로 데이터셋을 확장하는 방향이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기