GloTok: 전역 관계 학습으로 더 나은 이미지 토큰화를 실현하다
초록
기존 이미지 토큰화 방법의 한계인 지역적 의미 감독을 극복하기 위해, GloTok은 데이터셋 전체의 전역적 관계 정보를 활용하여 의미 코드북의 분포를 균일하게 만드는 새로운 토큰화 방법을 제안합니다. 코드북 간 히스토그램 관계 학습과 잔차 학습 모듈을 통해 재구성 품질을 높였으며, ImageNet 벤치마크에서 최고 수준의 재구성 및 생성 성능을 달성했습니다.
상세 분석
GloTok의 핵심 혁신은 ‘전역적(Global) 관점’을 도입한 의미 학습 방식에 있습니다. 기존 SOTA 방법들(DiGiT, FQGAN 등)은 사전 학습된 모델(CLIP, DINO)에서 추출한 개별 이미지의 특징을 사용하여 코드북을 지역적으로(Locally) 감독했습니다. 이는 배치 내 이미지들 간의 대조 학습에 그쳐, 전체 데이터셋에 걸친 광범위하고 균일한 의미 분포를 모델링하는 데 한계가 있었습니다. VA-VAE의 연구 결과처럼, 생성 모델의 성능은 잠재 표현의 균일성(Uniformity)과 밀접한 관련이 있습니다.
GloTok은 이 문제를 ‘코드북별 히스토그램 관계 학습(Codebook-wise Histogram Relation Learning)‘이라는 독창적인 방법으로 해결합니다. 먼저, 사전 학습된 모델의 특징을 클러스터링하거나 기존 토크나이저의 코드북을 이용하여 ‘선생님(Teacher)’ 토큰 세트를 구성합니다. 이 선생님 토큰 세트 내 모든 토큰 쌍 간의 코사인 유사도를 계산하고, 이를 구간별(-1부터 1까지) 히스토그램으로 표현하여 전역 관계 분포를 확보합니다. 동시에, GloTok이 학습 중인 ‘학생(Student)’ 의미 코드북에 대해서도 동일한 과정을 거쳐 관계 분포를 계산합니다. 최종적으로, KL 발산(Kullback-Leibler Divergence)을 사용하여 학생 코드북의 관계 분포가 선생님의 전역 관계 분포를 따르도록 제약합니다. 이는 단순한 특징 정렬이 아닌, 토큰 간 ‘관계 구조’ 자체를 전이하는 메타 학습에 가깝습니다. 이 방법의 부수적 장점은 학습 시 사전 학습된 모델에 직접 접근할 필요가 없어 계산 비용을 줄인다는 점입니다.
또 다른 중요한 기여는 ‘잔차 학습 모듈(Residual Learning Module)‘입니다. 양자화(Quantization)는 연속적 특징을 이산적 코드로 매핑하는 과정에서 필연적으로 정보 손실(세부纹理 손실)을 초래합니다. GloTok은 시각 및 의미 코드북 각각에 Transformer 블록으로 구성된 잔차 모듈을 도입합니다. 이 모듈은 양자화된 특징을 입력받아, 양자화 과정에서 손실된 원본 연속 특징과의 차이(Residual)를 예측합니다. 이 예측된 잔차를 양자화된 특징에 더함으로써, 보다 정교한 최종 표현을 얻어 재구성 품질을 높입니다.
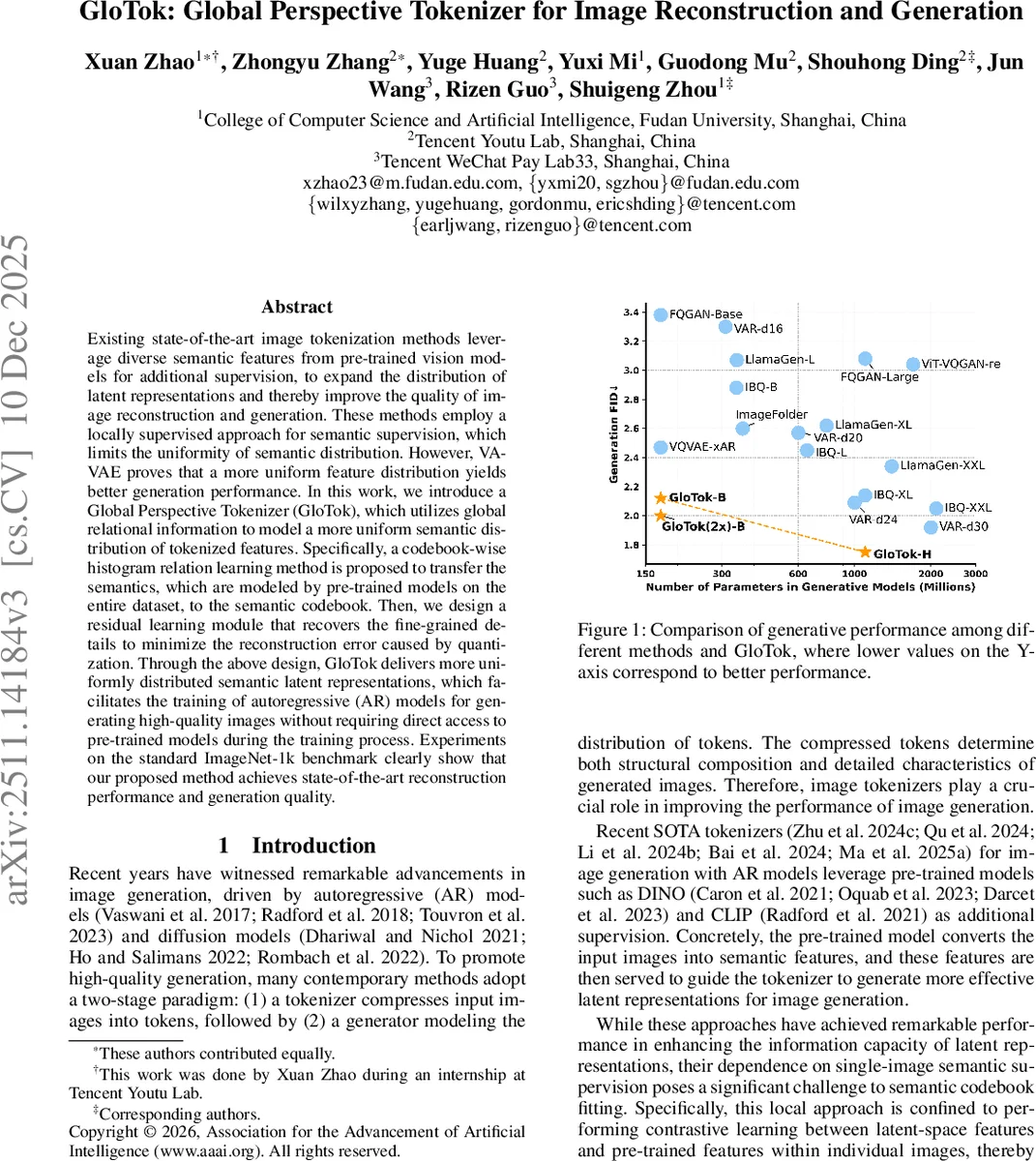
이러한 설계로 GloTok은 더 균일하고 정보 풍부한 잠재 공간을 구축하며, 이 토큰을 사용하는 후속 자기회귀(AR) 생성 모델의 성능 향상으로 이어집니다. 실험 결과(재구성 FID 0.83, 생성 FID 1.75)는 전역 관계 학습과 잔차 복원의 효과를 입증합니다. 이는 이미지 토큰화 연구가 단순히 사전 모델 특징을 ‘붙이는’ 단계에서, 분포의 질과 표현의 정밀도를 체계적으로 최적화하는 단계로 진화했음을 보여줍니다.
댓글 및 학술 토론
Loading comments...
의견 남기기