미지 얼굴을 위한 확장형 무참조 디모핑
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
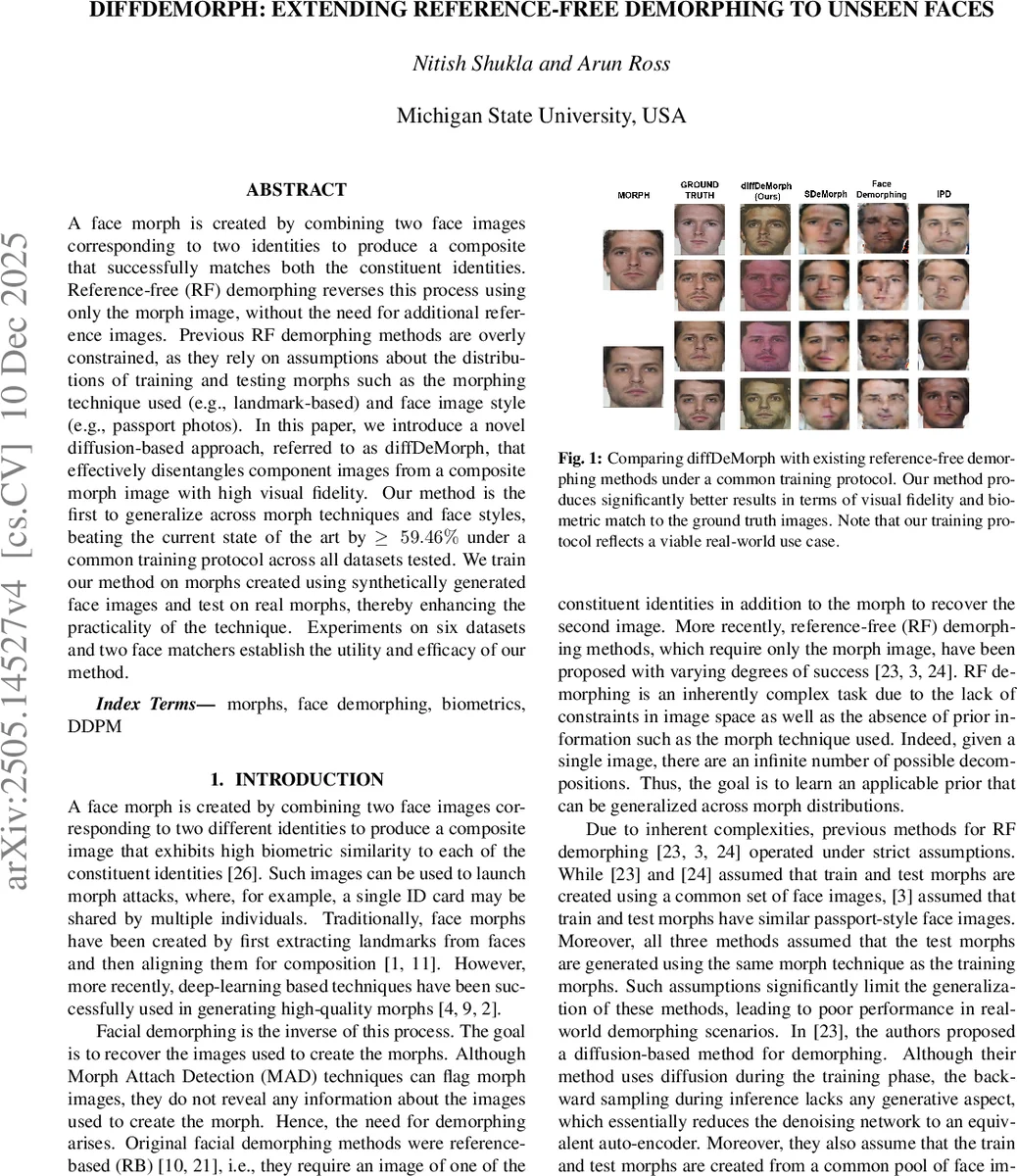
본 논문은 얼굴 모프 이미지만을 입력으로 두 원본 얼굴을 복원하는 무참조 디모핑 문제에 대해, 기존 방법이 가정하던 모프 기법·이미지 스타일 제한을 완전히 해제한 확산 기반 모델 diffDeMorph를 제안한다. 합성 얼굴 데이터를 이용해 학습하고, 실제 사진 기반 모프 데이터에 대해 높은 시각적 충실도와 매칭 정확도를 달성한다.
상세 분석
diffDeMorph는 확산 확률 모델(DDPM)을 기반으로, 두 원본 얼굴을 하나의 결합된 변수 (i₁,i₂) 로 취급하고 이를 모프 이미지 x 에 조건화한다. 기존 무참조 디모핑 연구는 (1) 학습·테스트 모프가 동일한 얼굴 풀(pool)에서 생성된다는 가정, (2) 동일한 랜드마크 기반 혹은 패스포트 스타일 이미지라는 전제에 의존해 일반화에 한계를 보였다. 본 연구는 이러한 가정을 전면 포기하고, 시나리오 3(학습·테스트 얼굴 풀 완전히 분리)까지 포함하는 가장 어려운 설정을 채택한다.
핵심 기법은 ‘모프‑가이드된 결합 디노이저’이다. 전통적인 DDPM은 텍스트나 클래스 라벨을 저차원 임베딩으로 삽입해 조건화를 수행하지만, diffDeMorph는 모프 이미지를 RGB 채널 그대로 디노이저 입력에 concatenate한다. 즉, 각 타임스텝 t 에서 디노이저는
댓글 및 학술 토론
Loading comments...
의견 남기기