관계 학습과 도메인 간 일반화 이론
초록
본 논문은 인간이 새로운 상황에 지식을 즉시 적용하는 능력을, 구조화된(기호적) 관계표현 위에서 이루어지는 유추 추론으로 설명한다. LISA와 DORA 모델을 확장해 비지도 시각 입력으로 관계표현을 학습하고, 강화학습과 결합해 비디오 게임과 심리 과제 사이의 제로샷 전이(Zero‑Shot Transfer)를 구현한다. 모델의 학습 궤적은 아동의 관계 발달과 일치한다.
상세 분석
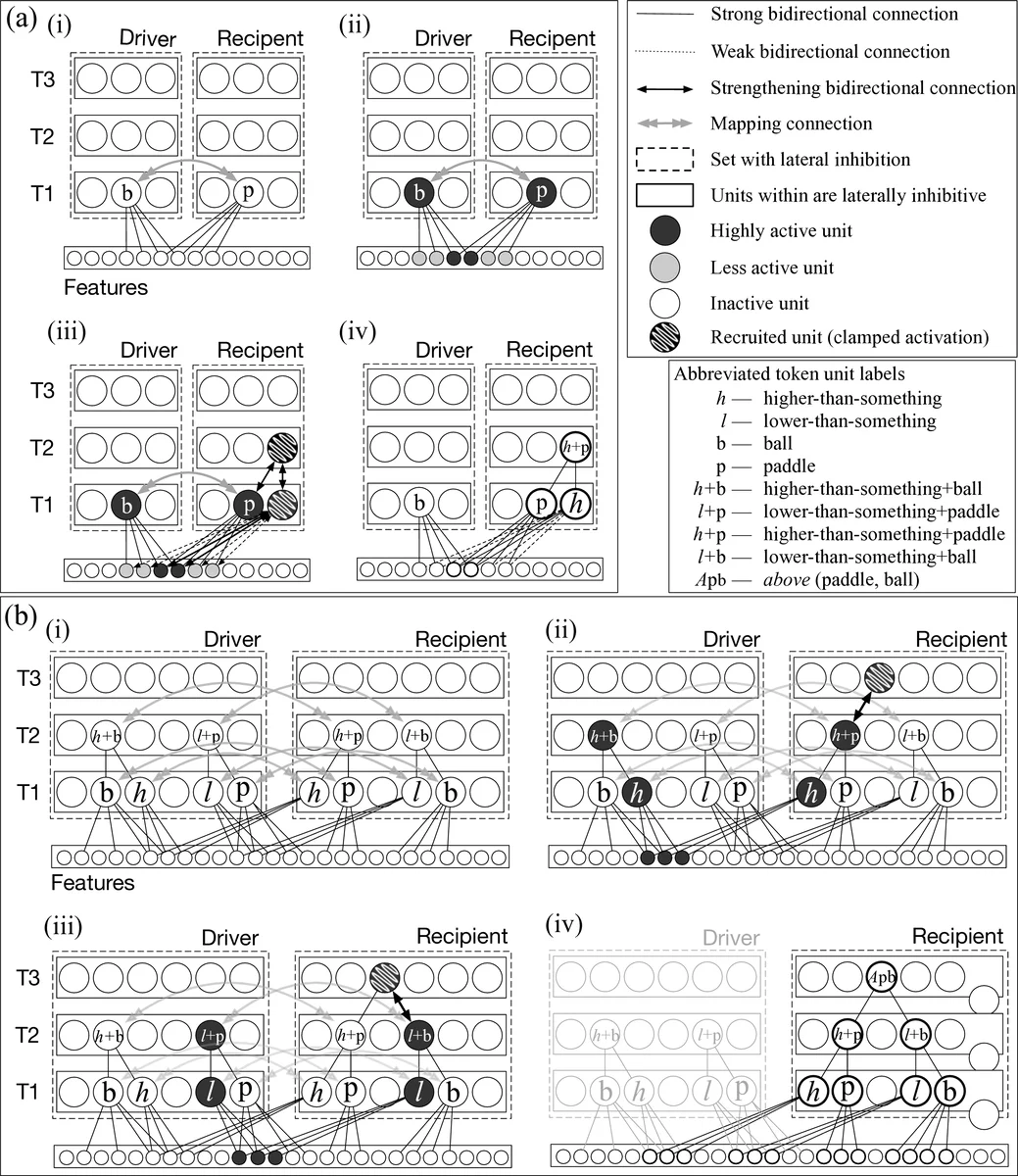
이 연구는 인간의 도메인 간 일반화가 단순한 통계적 연관 학습이 아니라, 구조화된 관계표현을 기반으로 한 아날로지 추론이라고 주장한다. 이를 구현하기 위해 기존의 LISA(Analogical Mapping)와 DORA(Relational Learning) 모델을 통합·확장하였다. 핵심은 두 단계 학습 메커니즘이다. 첫 번째 단계에서는 시각적 피처(예: 물체 위치, 크기, 색상)만을 입력으로 받아, 신경 진동(oscillatory binding) 메커니즘을 이용해 ‘왼쪽‑of’, ‘위‑에‑있다’ 등 관계를 추출한다. 이 과정은 지도 신호 없이도 입력 간의 일관된 패턴을 탐지함으로써 관계의 내용(content)(의미)과 형식(format)(인수‑역할 바인딩)를 동시에 형성한다. 두 번째 단계에서는 강화학습(RL) 에이전트가 학습된 관계표현을 정책 네트워크에 연결한다. 에이전트는 현재 상황에 가장 적합한 관계(예: ‘패들‑왼쪽‑볼’)를 선택하고, 선택된 관계에 기반한 행동(패들 이동)을 수행한다. 보상 신호는 게임 점수나 과제 성공률에서 얻어지며, 이를 통해 관계‑행동 매핑이 점진적으로 최적화된다.
모델의 제로샷 전이는 아날로지 매핑 메커니즘을 통해 이루어진다. 한 도메인(예: Breakout)에서 학습된 관계 네트워크는 구조적으로 동일한 관계(‘공‑위치‑패들’)를 다른 도메인(Pong)으로 그대로 매핑한다. 매핑 과정은 동일한 역할‑바인딩 구조를 유지하면서 인수(패들, 공)의 구체적 속성만 교체한다는 점에서 인간의 유추와 유사하다. 실험 결과, 모델은 첫 번째 Pong 시도에서 이미 Breakout에서 학습한 전략을 적용해 즉시 높은 성능을 보였으며, 이는 기존 딥러닝 기반 강화학습 에이전트가 수천 번의 시도 후에야 도달하는 수준과 대조된다.
발달적 측면에서는 아동이 관계 개념을 습득하는 순서(‘위‑아래’→‘앞‑뒤’→‘속도‑가속도’)와 모델의 학습 단계가 일치한다. 초기에는 단순한 공간 관계만 형성하고, 점차 복합 관계(‘동시‑동작’, ‘인과‑연쇄’)를 구축한다. 이는 LISA/DORA가 제시한 ‘관계 구조의 단계적 축적’ 가설을 실증적으로 뒷받침한다.
또한, 논문은 통계적 관계 학습(예: 관계 네트워크, 그래프 신경망)의 한계를 짚는다. 이러한 모델은 관계를 암묵적(weight matrix) 형태로 저장하므로 훈련 분포 밖의 조합에 취약하다. 반면, 명시적 구조화 관계표현은 **불변성(invariance)**을 보장해 입력 변동(위치, 색상, 스케일)에도 강건하게 작동한다. 저자는 신경 진동을 통한 바인딩이 이러한 불변성을 구현하는 핵심 메커니즘이라고 강조한다.
전체적으로 이 논문은 (1) 관계표현의 내용·형식 통합, (2) 강화학습과의 효율적 결합, (3) 제로샷 아날로지 전이 구현이라는 세 축을 통해 인간 수준의 도메인 간 일반화를 인공 시스템에 구현하는 새로운 패러다임을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기