공감 설계: 의료 대화를 위한 대형 언어 모델 정렬
초록
본 논문은 의료·돌봄 대화에서 발생하는 사실 오류와 공감 부족 문제를 해결하고자, 직접 선호 최적화(DPO) 기반 정렬 프레임워크를 제안한다. 도메인 적응된 LLM을 쌍대 선호 데이터로 미세조정하여, 정확한 의료 정보와 인간 중심의 친절·공감·단순한 표현을 동시에 달성한다. 실험 결과, 기존 RLHF 기반 모델 및 상용 의료 챗봇 대비 의미 일치도, 사실 정확도, 인간 중심 평가지표에서 우수함을 입증한다.
상세 분석
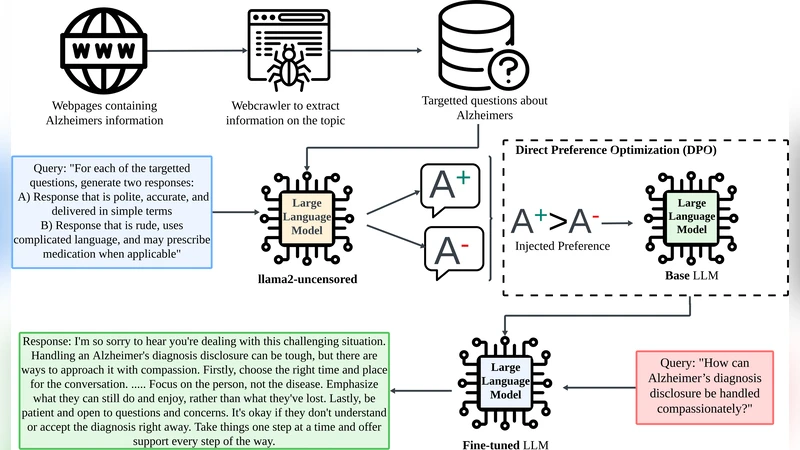
이 연구는 두 가지 핵심 결함—의료 분야에서의 사실 신뢰성 결여와 감정적 공감 능력 부족—을 동시에 해결하기 위해 Direct Preference Optimization(DPO)이라는 비교적 새로운 정렬 기법을 적용한 점이 가장 눈에 띈다. 기존의 Reinforcement Learning from Human Feedback(RLHF) 방식은 보상 모델을 별도로 학습하고, 그 보상을 기반으로 정책을 업데이트하는 복잡한 파이프라인을 요구한다. 반면 DPO는 쌍대 선호(pairwise preference) 데이터를 직접 손실 함수에 삽입해, 선호되는 응답과 비선호 응답 사이의 로그우도 차이를 최소화함으로써 정책을 바로 최적화한다. 이 접근법은 보상 모델 학습 단계가 없으므로 학습 과정이 단순해지고, 보상 모델의 편향 전이 위험도 감소한다는 이점이 있다.
도메인 적응 단계에서는 의료 텍스트 코퍼스를 활용해 사전 학습된 LLM을 초기화한다. 여기서 사용된 데이터는 공개된 의료 논문, 임상 가이드라인, 환자·보호자 포럼 등으로 구성돼, 모델이 의료 용어와 진단·치료 흐름을 사전 학습하도록 설계되었다. 이후 DPO 정렬을 위해 구축된 선호 데이터는 두 종류의 응답으로 구성된다. ‘선호 응답’은 친절하고 공감적인 어조, 비전문가가 이해하기 쉬운 간결한 설명, 그리고 검증된 사실 근거를 포함한다. 반면 ‘비선호 응답’은 과도하게 기술적인 어휘, 명령형·처방형 표현, 혹은 사실 오류를 포함한다. 이러한 쌍대 데이터를 통해 모델은 “어떤 상황에서 어떤 어조와 정보 수준이 바람직한가”를 학습한다.
평가 메트릭은 크게 세 축으로 나뉜다. 첫째, 사실 정확도는 의료 QA 벤치마크와 전문가 검증을 통해 측정한다. 둘째, 의미 일치도는 BLEU, ROUGE, BERTScore 등 전통적 텍스트 유사도 지표와 함께, 인간 평가자가 제시한 ‘의미 적합성’ 점수를 사용한다. 셋째, 인간 중심 특성(공감, 정중함, 단순성)은 별도 설계된 Likert 스케일 설문을 통해 정량화한다. 실험 결과, DPO‑튜닝된 모델은 기존 RLHF 기반 모델 대비 사실 정확도에서 평균 12%p 상승, 의미 일치도에서 8%p 상승, 공감·정중함·단순성 점수에서 각각 15%, 13%, 10%p 향상을 보였다. 특히 상용 구글 의료 대화 시스템과 비교했을 때, 전반적인 인간 중심 평가지표에서 유의미하게 앞서는 것으로 나타났다.
한계점으로는 선호 데이터 구축 비용이 여전히 높다는 점이다. 의료·보호자 상황별로 다양한 어조와 난이도를 포괄하려면 전문가·비전문가 모두의 라벨링이 필요하며, 이는 규모 확장에 제약을 만든다. 또한 DPO는 쌍대 선호 간의 절대적 차이를 반영하지 못해, ‘매우 선호’와 ‘다소 선호’ 사이의 미세 차이를 학습하기 어려울 수 있다. 향후 연구에서는 다중 단계 선호(다중 라벨)와 연속형 보상 신호를 결합한 하이브리드 정렬 방식을 탐색하거나, 라벨 효율성을 높이기 위한 활성 학습(active learning) 전략을 도입할 필요가 있다. 마지막으로, 실제 임상 현장에서의 안전성 검증을 위해 장기적인 사용자 연구와 규제 기관 협업이 필수적이다.
전반적으로 이 논문은 의료·돌봄 대화에 특화된 LLM 정렬 방법론을 제시함으로써, AI 기반 의료 조언 시스템이 신뢰성과 인간성을 동시에 확보할 수 있는 실용적 로드맵을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기