AI 소비자 지표: 일상 생활 과제 수행 능력 평가
초록
본 논문은 최신 AI 모델이 쇼핑·식품·게임·DIY 등 일상 소비자 과제를 얼마나 정확히 수행할 수 있는지를 측정하는 AI Consumer Index(ACE)를 제시한다. 400개의 비공개 테스트 케이스와 80개의 공개 개발 세트를 구성하고, 웹 검색을 활성화한 상태에서 10개 모델을 평가한다. 최고 성능 모델인 GPT‑5(Thinking=High)가 56.1% 점수를 기록했으며, 도메인별 성능 차이와 가격 정보 등 핵심 데이터의 환각 문제가 드러났다.
상세 분석
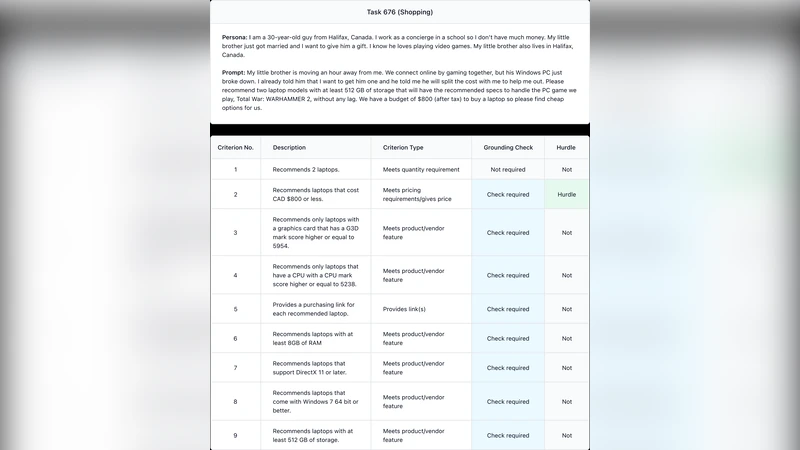
ACE는 “소비자‑중심” 벤치마크라는 새로운 패러다임을 제시한다는 점에서 의미가 크다. 기존 LLM 평가는 주로 언어 이해·생성 능력이나 특정 지식 질문에 초점을 맞추었지만, ACE는 실제 사용자가 일상에서 마주치는 구체적인 과업—예를 들어 온라인 쇼핑에서 최적 가격을 찾거나, 레시피 기반 식재료 구매, 게임 아이템 추천, DIY 프로젝트 부품 조달—을 시뮬레이션한다. 이는 모델이 단순히 텍스트를 생성하는 수준을 넘어, 외부 정보(웹 검색 결과)와의 연동, 그리고 그 정보에 대한 정확한 근거 제시가 필수적인 복합 과업을 포함한다는 점에서 기존 평가와 차별화된다.
데이터 구성은 두 단계로 이루어진다. 첫 번째는 80개의 공개 개발 세트를 CC‑BY 라이선스로 제공해 연구 커뮤니티가 모델 튜닝·프롬프트 엔지니어링에 활용하도록 설계했으며, 두 번째는 400개의 비공개 테스트 케이스를 숨김으로써 리더보드 조작을 방지한다. 각 도메인은 100개 케이스씩 균등하게 배분돼, 도메인 간 비교가 가능하도록 한다. 케이스 설계 시 “정답”이 단일 문자열이 아니라, 여러 가능한 정답(예: 동일 제품의 다양한 가격 옵션)과 “근거”(검색된 웹 페이지 URL 및 해당 문맥)으로 구성돼 있다.
평가 메트릭은 “동적 근거 검증”이라는 새로운 채점 방식을 도입한다. 모델이 생성한 응답에 포함된 핵심 정보(가격, 제품명, 레시피 재료 등)가 실제 검색된 웹 페이지에 존재하는지를 자동으로 확인한다. 이를 위해 텍스트 매칭 알고리즘과 페이지 레이아웃 파싱을 결합해, 단순 텍스트 일치뿐 아니라 의미적 일치까지 포괄한다. 이 과정에서 “부분 정답”도 부분 점수로 반영돼, 모델이 일부는 정확히 제공했지만 다른 부분에서 오류가 있더라도 정량적으로 평가할 수 있다.
실험 결과는 현재 최첨단 모델조차도 60% 미만의 종합 점수에 머물러 있음을 보여준다. GPT‑5(Thinking=High)가 56.1%로 1위를 차지했지만, 쇼핑 도메인에서는 48%에 그쳤다. 이는 가격 정보, 재고 상태, 배송 옵션 등 정밀한 수치가 요구되는 과업에서 모델이 “환각”을 일으키는 경향이 있음을 의미한다. 특히 “가격 환각”은 모델이 과거 학습 데이터에 기반해 평균 가격을 추정하거나, 실제 존재하지 않는 할인 정보를 만들어내는 형태로 나타났다. 반면, DIY 도메인에서는 비교적 높은 점수를 기록했는데, 이는 구체적인 부품 명칭과 사양이 웹에 명확히 표기된 경우가 많아 근거 검증이 용이했기 때문이다.
한계점으로는 (1) 웹 검색 엔진 자체의 최신성·정확성에 의존한다는 점, (2) 동적 근거 검증이 아직 완전 자동화되지 않아 일부 인간 검증이 필요하다는 점, (3) 테스트 케이스가 영어 기반 웹 콘텐츠에 편중돼 있어 비영어권 소비자 요구를 충분히 반영하지 못한다는 점을 들 수 있다. 또한 “Thinking” 모드(High/On/Off)의 정의가 모델 내부 구현에 따라 다를 수 있어, 외부 연구자가 동일 조건을 재현하기 어려운 점도 있다.
향후 연구 방향은 (①) 다언어·다문화 소비자 시나리오 확대, (②) 실시간 가격 변동·재고 업데이트를 반영한 동적 테스트 베드 구축, (③) 모델이 검색 결과를 “인용”하고, 인용된 근거를 사용자에게 투명하게 제시하도록 하는 인터페이스 설계, (④) 인간‑AI 협업 평가 프레임워크 도입으로 모델이 제공한 근거를 사용자가 직접 검증·수정할 수 있는 워크플로우 구축 등이 있다. 이러한 발전이 이루어질 경우, ACE는 AI가 실제 소비자 생활에 스며들기 위한 실용적 성능 기준을 제공하는 핵심 인프라가 될 것이다.