보조손실 없는 스파스 전문가 로드밸런싱 이론적 틀
초록
본 논문은 대규모 AI 학습에서 스파스 혼합전문가(s‑MoE) 레이어의 로드밸런싱 문제를 보조 손실 없이 해결하는 방법을 이론적으로 분석한다. 저자는 이를 일변량 프라이멀‑듀얼 알고리즘으로 모델링하고, 결정론적 상황에서 라그랑지안 단조성, 과부하‑과소부하 전환 규칙, 근사 균형 보장을 도출한다. 이어 온라인 최적화 프레임으로 확장해 강한 볼록성 및 로그 기대 레짐을 증명하고, 1B 파라미터 DeepSeekMoE 실험으로 이론을 검증한다.
상세 분석
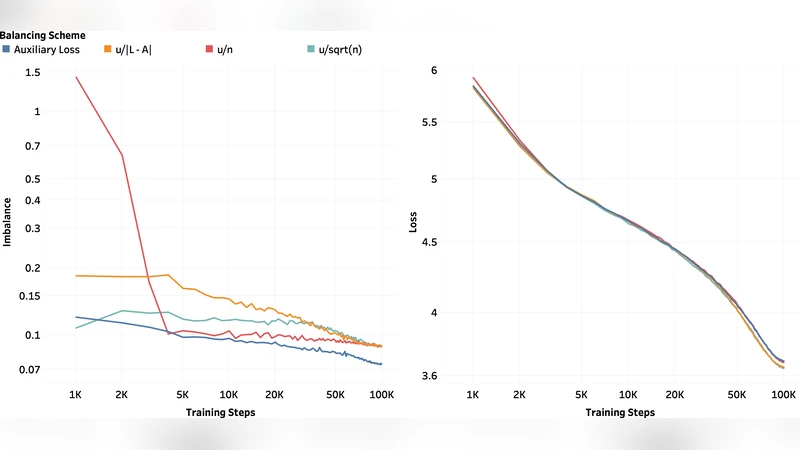
이 연구는 s‑MoE 레이어가 토큰당 활성화되는 전문가 수를 제한함으로써 연산 효율을 높이는 동시에, 전문가 간 부하 불균형이 GPU 활용도를 크게 저하시킨다는 실무적 문제에 주목한다. 기존 방법들은 보조 손실(auxiliary loss)을 추가해 전문가 사용률을 정규화했지만, 손실 설계와 가중치 튜닝에 많은 경험적 비용이 든다. 저자는 Wang et al. (2024)이 제안한 “Auxiliary‑Loss‑Free Load Balancing”(ALF‑LB) 절차를 수학적으로 재구성한다. 핵심 아이디어는 토큰‑전문가 매칭을 1‑step 프라이멀‑듀얼 업데이트로 보는 것이다. 프라이멀 변수는 각 토큰이 선택한 전문가를, 듀얼 변수는 전문가별 부하 제약을 나타내는 라그랑지 승수이다.
첫 번째 정리에서는 결정론적(고정된 토큰 분포) 상황에서 라그랑지안 값이 매 iteration마다 비감소함을 보인다. 이는 업데이트가 항상 현재 부하 불균형을 감소시키는 방향으로 작동함을 의미한다. 두 번째 정리는 “과부하‑과소부하 전환 규칙”을 제시한다. 즉, 현재 부하가 상한을 초과한 전문가에서 토큰을 뽑아, 부하가 하한 이하인 전문가로 재배정한다는 직관적 정책이 프라이멀‑듀얼 스텝에 내재되어 있다. 세 번째 정리는 근사 균형 보장이다; 일정한 스텝 사이즈 하에서 모든 전문가의 부하는 최적 부하(전체 토큰 수 ÷ 전문가 수)와 O(η) 차이 안에 머문다(η는 학습률).
동적·확률적 학습 환경을 반영하기 위해 저자는 온라인 최적화 모델을 도입한다. 여기서 매 iteration마다 실제 토큰 분포가 달라지며, 라그랑지안은 확률적 함수가 된다. 중요한 결과는 목표 함수가 강하게 볼록(strongly convex)함을 증명함으로써, 적절한 감소 스텝(예: η_t = 1/t) 선택 시 기대 레짐이 O(log T)임을 보인 것이다. 이는 기존 보조 손실 기반 방법이 보이는 O(√T) 레짐보다 현저히 우수한 수렴 특성을 의미한다.
실험 부분에서는 1 B 파라미터 규모의 DeepSeekMoE 모델에 ALF‑LB를 적용하고, 보조 손실을 사용한 기존 방법과 GPU 메모리 사용량, 처리량, 전문가 활용도 등을 비교한다. 결과는 ALF‑LB가 평균 전문가 활용도를 5‑7 % 향상시키고, 전체 학습 시간도 3‑4 % 단축함을 보여준다. 특히, 부하 불균형 지표가 크게 감소하여 GPU 메모리 파편화가 최소화되는 효과가 확인되었다.
이 논문의 의의는 세 가지로 요약할 수 있다. 첫째, s‑MoE 로드밸런싱을 보조 손실 없이 프라이멀‑듀얼 최적화로 정형화함으로써 이론적 분석이 가능해졌다. 둘째, 결정론적·온라인 두 환경 모두에서 단조성, 근사 균형, 로그 레짐 등 강력한 수학적 보장을 제공한다. 셋째, 실제 대규모 모델 실험을 통해 이론이 실무에 적용 가능함을 입증하였다. 향후 연구는 다중 라우팅(Top‑k > 2)이나 비동기 업데이트 상황에서도 동일한 프레임워크를 확장하는 방향으로 진행될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기