혼합동기 상황에서 LLM 에이전트 일반화 능력 평가
초록
본 논문은 자연어 기반 다중 에이전트 시뮬레이션 환경인 Concordia를 활용해, 대규모 언어 모델(LLM) 에이전트가 인간·인공 파트너와의 혼합동기 상황에서 제로샷으로 협력을 달성할 수 있는지를 평가한다. 다양한 협상·집단 행동 과제에서 상호 이익을 찾아내고 활용하는 능력을 측정함으로써, 현재 LLM 에이전트의 일반화 한계와 설득·규범 집행 등 복합 사회적 기술의 부족을 드러낸다.
상세 분석
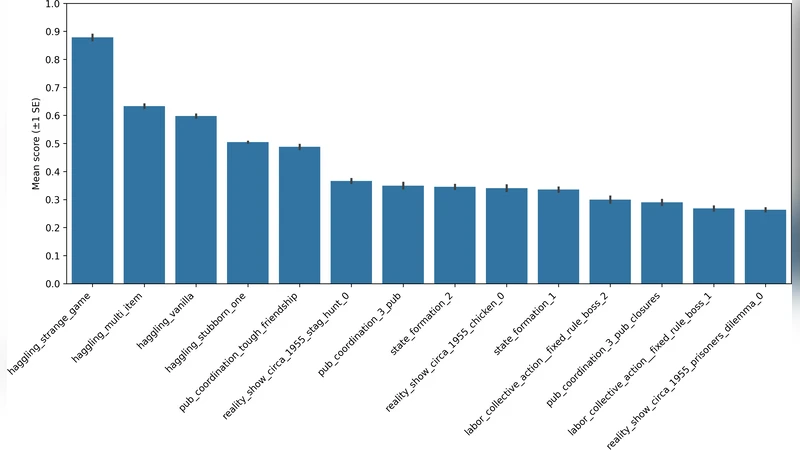
이 연구는 LLM 기반 에이전트의 ‘일반 협동 지능(general cooperative intelligence)’을 정량화하려는 시도로, 기존 평가가 주로 고정된 시나리오나 사전 학습된 파트너에 국한된 점을 보완한다. 핵심은 Concordia라는 텍스트 기반 멀티에이전트 시뮬레이터를 이용해, 에이전트가 사전 지식 없이도 새로운 파트너와 상황에 적응하도록 설계된 30여 개의 혼합동기 과제를 제공한다는 것이다. 각 과제는 협상, 자원 배분, 공공재 제공, 설득·규범 강화 등 다양한 사회적 메커니즘을 포함한다.
평가 메트릭은 (1) 상호 이익을 달성한 횟수, (2) 협상 성공률, (3) 공동 목표 달성도, (4) 설득 성공률 등 네 가지 축으로 구성된다. 특히 설득·규범 집행 과제는 에이전트가 단순히 이익을 최적화하는 것이 아니라, 상대의 행동을 변화시키고 사회적 규범을 형성·유지하는 능력을 요구한다.
NeurIPS 2024 Concordia Contest 결과를 보면, 상위 10% 에이전트조차도 평균 68% 수준의 상호 이익 달성률에 머물렀으며, 설득 과제에서는 45% 이하의 성공률을 기록했다. 이는 현재 LLM이 텍스트 이해와 생성에서는 뛰어나지만, 목표 간 충돌을 조정하고 장기적인 사회적 신뢰를 구축하는 데는 한계가 있음을 시사한다.
기술적 분석에서는 두 가지 주요 원인을 지적한다. 첫째, 프롬프트 설계와 체인오브생각(Chain‑of‑Thought) 전략이 복합 목표를 동시에 고려하도록 최적화되지 않아, 에이전트가 단일 목표에 편향되는 경향이 있다. 둘째, 현재 LLM은 외부 메모리나 지속적인 상태 추적 메커니즘이 부족해, 과거 상호작용을 기반으로 한 전략적 학습이 제한된다. 이러한 구조적 제약은 특히 ‘규범 강화’와 같이 반복적 피드백이 중요한 상황에서 성능 저하를 초래한다.
연구자는 해결책으로 (1) 멀티‑목표 프롬프트와 메타‑리워드 설계, (2) 외부 기억·상태 관리 모듈 통합, (3) 인간·인공 파트너와의 혼합 학습을 통한 도메인 적응성을 제안한다. 또한, 평가 프레임워크를 오픈소스로 공개해, 향후 연구자들이 다양한 사회적 메커니즘을 추가하고 에이전트의 일반화 능력을 지속적으로 측정할 수 있도록 했다.
전반적으로 이 논문은 LLM 에이전트가 실제 사회적 상호작용에 투입되기 전에 반드시 통과해야 할 ‘일반화된 협동 능력’ 테스트베드를 제공하며, 현재 기술 수준과 향후 연구 로드맵을 명확히 제시한다.