단순 에이전트, 전문가를 넘어선 바이오이미징 워크플로 최적화
초록
본 논문은 제한된 라벨 데이터만으로도 기존의 생산 수준 컴퓨터 비전 툴을 새로운 바이오이미징 데이터에 맞게 자동으로 적응시키는 간단한 LLM 기반 에이전트 프레임워크를 제안한다. 세 가지 대표 파이프라인(Polaris, Cellpose, MedSAM)에 대해 베이스 에이전트와 다양한 설계 변형을 체계적으로 평가한 결과, 복잡한 설계보다 기본적인 코드 생성·실행 루프가 인간 전문가가 만든 최적화 코드보다 일관되게 높은 성능을 보였다. 또한 복잡한 구성 요소(전문가 함수, 함수 은행, AutoML 튜닝 등)는 작업마다 효과가 다르며, 전체적인 설계 로드맵을 제시한다.
상세 분석
이 연구는 “툴 적응”이라는 구체적 문제에 초점을 맞추어, 일반적인 과학용 AI 에이전트가 반드시 복잡해야 할 필요는 없다는 가설을 검증한다. 저자들은 베이스 에이전트를 ‘Task Prompt’, ‘Data Prompt’, ‘API List’를 포함한 세 가지 입력 요소와 ‘Coding Agent’, ‘Execution Agent’ 두 개의 핵심 모듈로 구성하였다. Coding Agent는 LLM을 이용해 전처리·후처리 파이썬 함수를 생성하고, Execution Agent는 이를 실제 파이프라인에 삽입해 검증 데이터셋으로 평가한다. 이때 피드백 루프를 통해 점수를 반환받아 다음 반복에 활용한다.
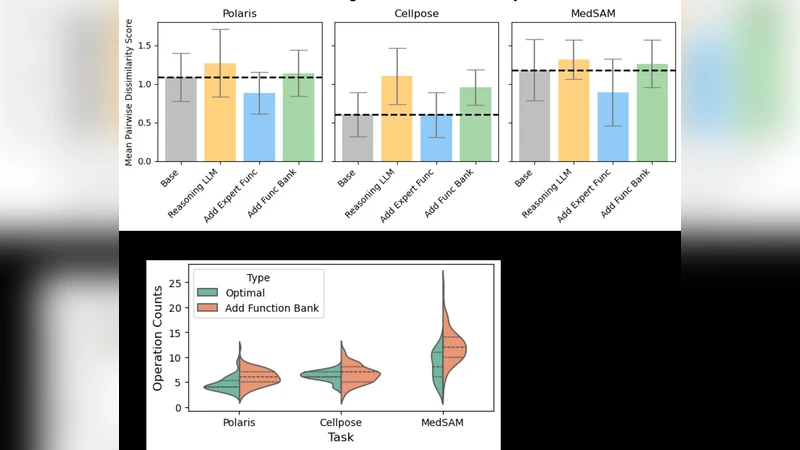
설계 공간은 네 가지 축으로 확장되었다. 첫째, LLM 종류(GPT‑4.1, o3, Llama 3.3‑70B)로 모델 규모와 추론 능력을 비교하였다. 둘째, 전문가가 사전에 만든 최적화 함수들을 프롬프트에 포함시켜 인‑컨텍스트 학습 효과를 검증했다. 셋째, 함수 은행을 도입해 이전에 생성된 상위·하위 함수들을 재활용함으로써 탐색 효율성을 높였다. 넷째, AutoML 모듈을 추가해 하이퍼파라미터 탐색을 별도로 수행하도록 했다.
세 가지 실제 바이오이미징 파이프라인에 대해 20번씩 시드 변화를 주어 60회의 시도(각 20 iteration × 3 function pairs)를 수행했으며, 과적합 방지를 위해 전체 실행 중 상위 15개의 함수를 선정해 테스트 성능을 보고했다. 결과는 다음과 같다. 베이스 에이전트만으로도 Polaris(F1 0.867), Cellpose(AP@IoU 0.409), MedSAM(NSD+DSC 0.971)에서 전문가 베이스라인을 모두 초과했다. 특히 MedSAM에서는 0.151 포인트 상승이라는 큰 개선을 보였다.
흥미롭게도 ‘Small LLM’(Llama 3.3‑70B)은 대부분의 경우 전문가 수준에 못 미쳤으며, 이는 모델 규모와 추론 능력이 제한적일 때 복잡한 이미지 전처리·후처리 로직을 정확히 생성하기 어려움을 시사한다. 반면 ‘Reasoning LLM’(o3)이나 ‘GPT‑4.1’은 일관된 성능 향상을 제공했지만, 추가적인 설계 요소(전문가 함수, 함수 은행, AutoML)들은 작업마다 효과가 상이했다. 예를 들어 함수 은행을 사용하면 Polaris와 Cellpose에서는 약간의 성능 저하가 있었지만 MedSAM에서는 오히려 개선되었다. AutoML 모듈은 하이퍼파라미터 미세조정에 도움이 되었지만, 전체 파이프라인 실행 비용이 증가하는 단점이 있었다.
이러한 분석을 통해 저자들은 “단순함이 최선”이라는 결론에 도달한다. 복잡한 계층적 플래닝이나 대규모 툴 스페이스를 갖춘 에이전트는 특정 도메인 적응 작업에 불필요한 오버헤드를 초래한다. 대신, 명확한 데이터·API 컨텍스트와 적절한 LLM 선택만으로도 충분히 높은 성능을 달성할 수 있다. 또한, 설계 선택이 작업 특성에 따라 달라질 수 있음을 강조하며, 실무에서 적용 가능한 설계 로드맵을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기