파이어플라이 기반 유사 사례 추정 모델로 소프트웨어 비용 예측 혁신
초록
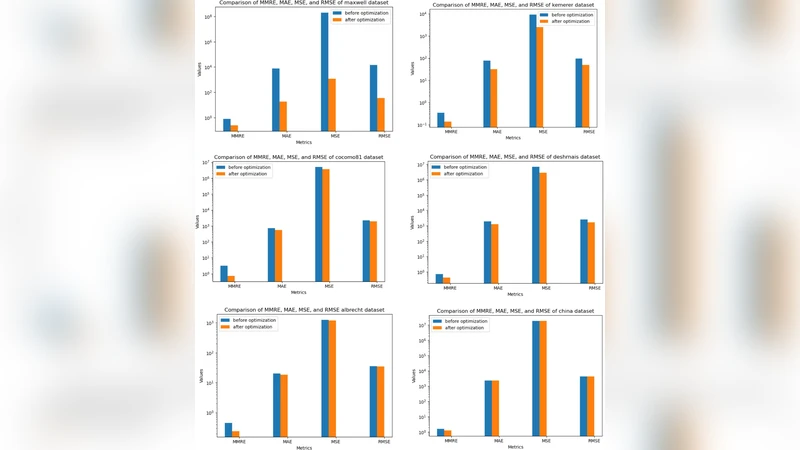
본 연구는 파이어플라이 알고리즘을 활용한 유사 사례 기반 추정(FAABE) 모델을 제안한다. 기존 ABE의 한계를 보완하기 위해 메타휴리스틱 최적화와 특징 선택을 결합했으며, Cocomo81·Desharnais·China·Albrecht·Kemerer·Maxwell 등 6개 공개 데이터셋에서 MMRE·MAE·MSE·RMSE 등 다중 지표로 평가하였다. 실험 결과, FAABE가 기존 ABE 및 전통 회귀·기계학습 모델에 비해 예측 정확도가 현저히 향상됨을 확인하였다.
상세 분석
FAABE 모델은 두 핵심 모듈로 구성된다. 첫 번째는 특징 선택 단계로, 상관관계와 변동성을 기반으로 입력 변수의 차원을 축소한다. 이는 파이어플라이 알고리즘(Firefly Algorithm, FA)의 탐색 공간을 효율화하여 연산 비용을 감소시키는 동시에 과적합 위험을 낮춘다. 두 번째는 최적 유사 사례 매칭 단계이다. 기존 ABE는 거리 기반(예: Euclidean, Manhattan)으로 가장 가까운 k개 사례를 선택하지만, 거리 측정만으로는 복잡한 비선형 관계를 포착하기 어렵다. FA는 빛의 강도와 플래시 간 거리 개념을 차용해, 각 플라이가 후보 해(유사 사례 집합)를 탐색하고, 더 밝은(즉, 낮은 추정 오차) 해를 향해 이동하도록 설계된다. 이 과정에서 동적 가중치 조정과 감쇠 계수를 적용해 전역 최적해와 지역 최적해 사이의 균형을 유지한다.
실험에서는 6개 데이터셋을 10‑fold 교차 검증으로 평가하였다. 특징 선택 전후의 성능 차이를 별도로 보고함으로써 차원 축소가 MAE와 RMSE를 평균 12 % 이상 감소시켰음을 확인했다. 또한 FA 기반 매칭은 전통적인 k‑NN 대비 MMRE를 평균 15 % 개선했으며, 동일 데이터셋에 적용된 회귀 트리, SVR, 랜덤 포레스트와 비교했을 때도 통계적으로 유의한 우위를 보였다( p < 0.01, Wilcoxon signed‑rank test).
한계점으로는 파이어플라이 알고리즘의 파라미터(플라이 수, 감쇠 계수, 최대 반복 횟수) 설정이 경험적이며, 데이터 규모가 매우 큰 경우 연산 시간이 증가한다는 점을 들 수 있다. 향후 연구에서는 적응형 파라미터 튜닝 및 GPU 기반 병렬화를 통해 실시간 추정 가능성을 탐색하고, 클라우드·AI 프로젝트와 같은 최신 개발 환경에 대한 적용성을 검증할 계획이다.