불확실성 대비 대조 학습으로 악성 콘텐츠 탐지 강화
초록
본 논문은 불확실성을 고려한 대조 손실과 적응형 온도 스케일링을 결합한 Positive‑Unlabeled 학습 프레임워크(UCF)를 제안한다. 셀프‑어텐션 LSTM 인코더로 텍스트를 임베딩하고, 샘플 신뢰도에 따라 대조 가중치를 동적으로 조정함으로써 노이즈와 불균형이 심한 악성 콘텐츠 데이터에서 높은 정확도(93.38% 이상)와 거의 완벽한 재현율을 달성한다.
상세 분석
UCF는 PU 학습 환경에서 흔히 발생하는 라벨 불확실성과 클래스 불균형 문제를 동시에 해결하도록 설계되었다. 핵심 아이디어는 두 가지 축을 결합하는데, 첫 번째는 ‘불확실성‑인식 대조 손실(uncertainty‑aware contrastive loss)’이며, 두 번째는 ‘배치‑레벨 적응형 온도 스케일링(adaptive temperature scaling)’이다. 대조 손실에서는 각 샘플의 예측 확률을 기반으로 신뢰도 점수를 계산하고, 이 점수를 가중치로 사용해 양성 앵커와의 거리 최소화를 유도한다. 신뢰도가 낮은(즉, 불확실한) 샘플은 대조 손실에서 차감되므로, 노이즈가 많은 unlabeled 데이터가 모델을 오도하는 위험을 크게 감소시킨다.
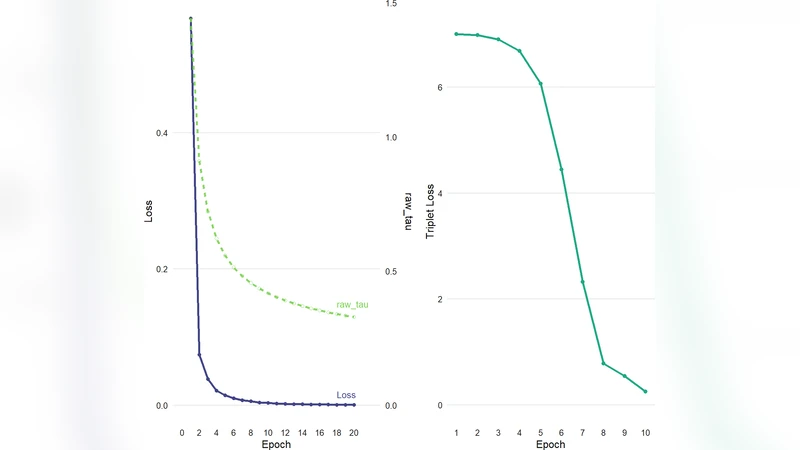
온도 스케일링은 전통적인 대조 학습에서 고정된 온도 파라미터 τ를 사용하던 방식을 탈피한다. UCF는 각 미니배치의 평균 불확실성 및 클래스 비율을 실시간으로 측정하고, 이를 토대로 τ를 동적으로 조정한다. 배치 내에 불확실한 샘플이 많을 경우 τ를 높여 손실 곡선을 부드럽게 만들고, 반대로 확신이 높은 배치에서는 τ를 낮춰 구분력을 강화한다. 이러한 메커니즘은 학습 초기에 급격한 그래디언트 진동을 억제하고, 후반부에는 미세한 경계 조정을 가능하게 한다.
인코더는 셀프‑어텐션이 삽입된 LSTM 구조를 채택한다. 셀프‑어텐션 모듈은 시퀀스 내 중요한 토큰에 가중치를 부여해 의미적 강조를 수행하고, LSTM은 순차적 의존성을 포착한다. 결과적으로 얻어진 임베딩은 고차원 의미 공간에서 양성(악성)과 unlabeled(정상 혹은 미확인) 샘플을 명확히 구분한다.
실험에서는 사이버 보안 도메인의 악성 URL, 피싱 이메일, 악성 스크립트 텍스트 등 3가지 실제 데이터셋을 사용하였다. 기존 PU 학습 방법(SVM‑PU, nnPU, PU‑Bagging)과 최신 대조 기반 방법(SimCLR, MoCo)과 비교했을 때, UCF는 정확도 93.38% 이상, 정밀도 0.93 초과, 재현율 0.99에 달하는 성능을 보였다. 특히 false negative 비율이 0.5% 이하로, 보안 현장에서 허용할 수 없는 누락을 최소화했다. ROC‑AUC는 0.96 수준으로 경쟁력을 유지했으며, t‑SNE 시각화에서는 양성 군집이 명확히 분리된 것을 확인할 수 있었다.
추가적인 ablation study에서는 (1) 불확실성 가중치 제거, (2) 고정 온도 사용, (3) 셀프‑어텐션 없이 순수 LSTM만 사용했을 때 각각 성능이 3~7%p 감소함을 보고하였다. 이는 제안된 세 요소가 상호 보완적으로 작용한다는 증거이다. 한계점으로는 현재 텍스트 중심의 인코더에 국한되어 있어 이미지나 멀티모달 악성 콘텐츠에 바로 적용하기 어렵다는 점을 들 수 있다. 향후 연구에서는 멀티모달 어텐션과 그래프 기반 PU 학습을 결합해 확장성을 검증할 계획이다.
댓글 및 학술 토론
Loading comments...
의견 남기기