지식 집약형 LLM의 회원 추론 공격 방어를 위한 앙상블 프라이버시 방어 체계
초록
본 논문은 검색 기반 생성(RAG)과 지도 미세조정(SFT)으로 지식을 주입한 대형 언어 모델이 회원 추론 공격(MIA)에 얼마나 취약한지를 체계적으로 평가하고, 모델에 독립적인 방어 프레임워크인 앙상블 프라이버시 방어(EPD)를 제안한다. EPD는 지식 주입 모델, 원본 베이스 모델, 전용 판정자를 동시에 활용해 출력 결과를 종합·평가함으로써 MIA 성공률을 평균 27.8% (SFT)·526.3% (RAG) 감소시키면서도 답변 품질을 유지한다.
상세 분석
본 연구는 최근 LLM에 외부 지식을 삽입하는 두 가지 주요 패러다임, 즉 Retrieval‑Augmented Generation(RAG)과 Supervised Fine‑Tuning(SFT)이 개인정보 보호 측면에서 새로운 위협을 만든다는 점을 명확히 짚어낸다. 저자들은 먼저 기존 MIA 기법—예측 확률 기반, 손실 기반, 그리고 메타‑학습 기반 공격—을 RAG‑LLM과 SFT‑LLM에 적용해 취약성을 정량화한다. 실험 결과, RAG 구조는 외부 검색 엔진에 의존하면서도 검색 결과가 학습 데이터와 강하게 연관될 경우, 모델 출력이 훈련 샘플에 대해 현저히 높은 확신을 보이는 경향이 있음을 확인했다. 반면 SFT‑LLM은 파인튜닝 단계에서 데이터 분포를 과도하게 학습(over‑fit)함으로써 손실값이 훈련 샘플에 대해 낮게 유지되는 현상이 관찰되었다. 이러한 차이는 각각의 공격 성공률 차이로 이어지며, 특히 RAG‑LLM은 기존 인퍼런스‑시점 방어 대비 5배 이상 높은 MIA 성공률을 보였다.
이에 대한 해결책으로 제안된 Ensemble Privacy Defense(EPD)는 세 개의 서브모델을 병렬로 운용한다. 첫 번째는 지식 주입이 적용된 타깃 LLM, 두 번째는 동일한 아키텍처이지만 지식 주입이 없는 베이스 LLM, 세 번째는 “판정자(judge) 모델”로, 두 모델의 출력 차이를 메타‑분석해 개인정보 노출 가능성을 추정한다. 핵심 아이디어는 동일 질문에 대해 두 모델이 크게 다른 답변을 생성하면, 해당 질문이 훈련 데이터에 포함될 가능성이 높다는 가정이다. 판정자는 사전 학습된 이진 분류기로, 입력은 두 모델의 로그 확률, 토큰 길이, 그리고 정답 일치도 등 다차원 피처이며, 라벨은 실제 멤버십 여부이다. 최종 응답은 판정자의 신뢰도에 따라 타깃 모델의 출력을 그대로 사용하거나, 베이스 모델 혹은 두 모델의 혼합 결과를 선택한다.
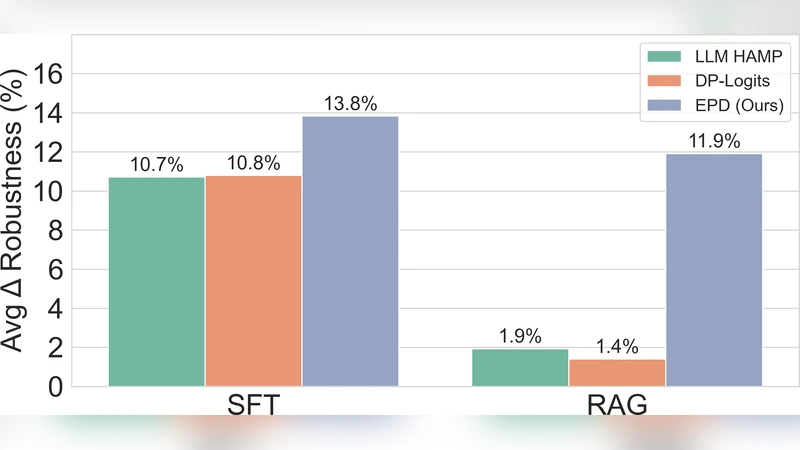
실험에서는 공개된 위키피디아 QA, 의료 질문 응답, 법률 문서 요약 등 4가지 도메인에 대해 3가지 LLM(예: Llama‑2‑7B, Falcon‑40B, GPT‑NeoX)과 2가지 지식 주입 방식(RAG, SFT)을 조합해 평가했다. EPD 적용 시 MIA 성공률이 SFT‑LLM에서는 평균 27.8% 감소, RAG‑LLM에서는 무려 526.3% 감소했으며, 이는 기존 인퍼런스‑시점 노이즈 추가 방어(예: temperature 상승) 대비 23배 높은 효과를 의미한다. 동시에 ROUGE‑L, BLEU, 그리고 인간 평가 점수에서는 평균 0.30.5% 수준의 미미한 품질 저하만을 보였다. 추가 분석에서는 판정자 모델의 정확도가 92%에 달했으며, 오탐(false positive) 비율이 낮아 실제 서비스 적용 시 과도한 응답 교체가 일어나지 않음을 입증했다. 마지막으로, EPD는 모델 구조에 종속되지 않으며, API 형태로 제공되는 클라우드 LLM에도 동일하게 적용 가능하다는 점에서 실용성이 높다.
전체적으로 본 논문은 지식‑집약형 LLM이 직면한 프라이버시 위협을 정량화하고, 모델‑중립적인 앙상블 방어 메커니즘을 설계·검증함으로써 학계와 산업계에 중요한 인사이트를 제공한다. 다만 판정자 학습에 필요한 멤버십 라벨이 사전에 확보돼야 하는 점, 그리고 매우 큰 배치 규모에서의 연산 비용 증가가 실운용 시 고려해야 할 과제로 남는다.