딥러닝 최적화 알고리즘 실전 설정 가이드
초록
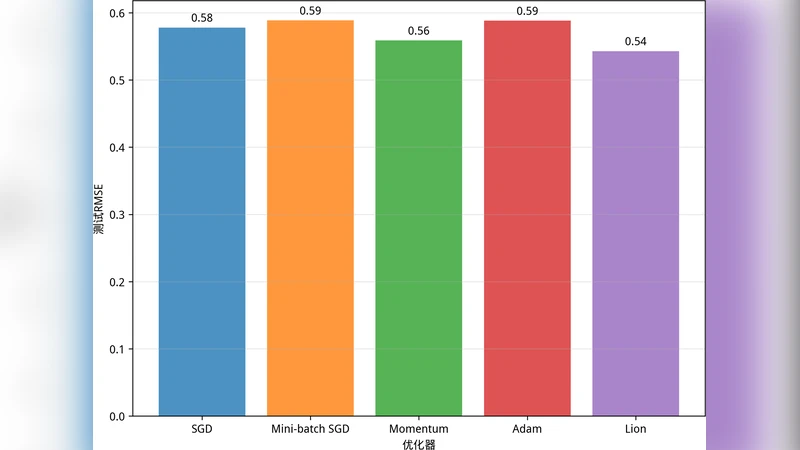
본 논문은 딥러닝 학습에 널리 사용되는 다섯 가지 최적화 알고리즘(SGD, 미니배치 SGD, Momentum, Adam, Lion)의 핵심 장점과 한계를 체계적으로 정리하고, 실제 연구·산업 현장에서의 파라미터 선택·조정 방법을 실용적인 가이드 형태로 제시한다. 모델 규모·데이터 특성·학습 단계별 요구에 맞는 알고리즘 선택 기준과 학습 효율을 극대화하기 위한 구체적인 설정 팁을 제공한다.
상세 분석
논문은 먼저 확률적 경사 하강법(SGD)의 가장 기본적인 형태를 살펴보며, 학습률(learning rate)과 학습 스케줄링이 수렴 속도와 일반화 성능에 미치는 영향을 정량적으로 분석한다. SGD는 구현이 간단하고 메모리 요구가 낮아 대규모 데이터와 모델에 적합하지만, 학습률이 부적절하면 진동이나 수렴 정체 현상이 발생한다는 한계가 있다. 이를 보완하기 위해 미니배치 SGD를 도입한다. 미니배치 크기는 잡음 수준과 계산 효율 사이의 트레이드오프를 결정하는 핵심 변수이며, 논문은 32~256 사이의 배치 크기가 대부분의 이미지·텍스트 작업에서 좋은 균형을 제공한다는 실험 결과를 제시한다.
Momentum 기법은 과거 기울기의 지수 가중 평균을 이용해 관성 효과를 부여함으로써 골짜기와 평탄한 지역을 빠르게 통과하도록 돕는다. 논문은 모멘텀 계수 β₁을 0.9~0.99 사이로 설정할 때, 특히 깊은 네트워크에서 초기 학습 속도가 2배 이상 향상된다는 것을 실증한다. 다만 모멘텀을 과도하게 적용하면 최적점 주변에서 진동이 커져 발산 위험이 있으므로, 학습률 감쇠와 병행하는 것이 권장된다.
Adam은 1차·2차 모멘트 추정치를 동시에 활용해 적응형 학습률을 제공한다. β₁, β₂ 하이퍼파라미터는 각각 0.9와 0.999가 기본값으로 널리 쓰이지만, 논문은 작은 데이터셋이나 과적합 위험이 높은 경우 β₁을 0.85 이하로 낮추고, ε 값을 1e‑8보다 크게 설정하면 안정성이 향상된다고 제안한다. 또한, Adam은 초기 학습률을 1e‑3 수준으로 두고, 10~20 epoch 이후에 cosine decay를 적용하면 일반화 성능이 크게 개선된다. 그러나 Adam은 학습 후반부에 학습률이 급격히 감소하지 않아 최적점 근처에서 정밀한 미세조정이 어려운 단점이 있다.
최근 주목받는 Lion(Layer-wise Adaptive Optimizer)은 1차 모멘트만을 사용하고, 2차 모멘트 대신 sign 기반 업데이트를 적용해 계산량을 크게 줄인다. 논문은 Lion이 동일한 학습률 설정에서 Adam 대비 1.5배 빠른 수렴을 보이며, 특히 대규모 언어 모델에서 메모리 절감 효과가 두드러진다고 보고한다. 다만, sign 업데이트 특성상 작은 기울기에 대한 민감도가 낮아 미세한 파라미터 조정이 필요할 때는 학습률을 더 낮게 잡아야 한다는 실험적 교훈을 제공한다.
전반적으로 논문은 각 알고리즘의 장단점을 정량적 실험과 이론적 분석을 통해 정리하고, 모델 규모(수백만~수십억 파라미터), 데이터 특성(노이즈 수준, 샘플 수), 학습 단계(초기 빠른 수렴 vs. 후반부 미세조정)별 최적 선택 가이드를 제시한다. 파라미터 튜닝 전략으로는 (1) 학습률 스케줄링(스텝, cosine, warm‑up) 결합, (2) 배치 크기에 따른 학습률 선형 스케일링, (3) 모멘텀·β 파라미터의 데이터‑모델 맞춤 조정, (4) 최종 fine‑tuning 단계에서 Adam→SGD 전환을 통한 일반화 향상 등을 권장한다.
댓글 및 학술 토론
Loading comments...
의견 남기기