활성 슬라이스 탐색: 오류 구간을 빠르게 찾아내는 효율적 방법
초록
본 논문은 대형 언어 모델(LLM)의 특정 오류 구간(슬라이스)을 최소한의 라벨링 비용으로 발견하기 위해 ‘활성 슬라이스 탐색(Active Slice Discovery)’ 프레임워크를 제안한다. 다양한 특성 표현과 활성 학습 전략을 실험한 결과, 불확실성 기반 알고리즘이 2~10%의 슬라이스 멤버십 정보만으로도 높은 탐색 정확도를 달성함을 확인하였다.
상세 분석
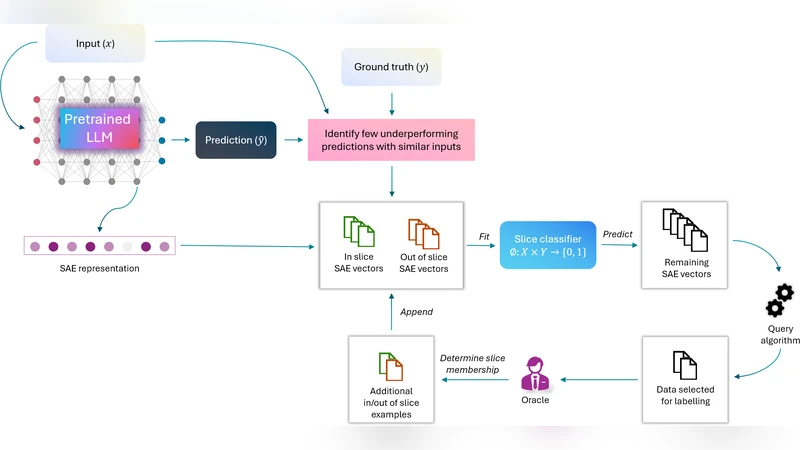
본 연구는 LLM이 특정 하위 집단에서 일관된 오류를 보이는 현상을 ‘오류 슬라이스’라는 개념으로 정의하고, 이러한 슬라이스를 효율적으로 식별하기 위한 방법론을 체계화하였다. 핵심 아이디어는 인간 annotator의 비용을 최소화하기 위해 모델이 예측한 오류 샘플을 먼저 군집화하고, 그 군집에 속한 샘플들이 동일한 오류 패턴을 공유하는지를 제한된 질의 횟수로 검증하는 것이다. 이를 위해 저자들은 ‘활성 슬라이스 탐색(Active Slice Discovery)’이라는 새로운 문제 설정을 제안하고, 이를 두 단계로 분해하였다. 첫 번째 단계는 후보 오류 샘플을 특성 공간에 매핑하고, 두 번째 단계는 활성 학습(active learning) 전략을 적용해 가장 정보량이 높은 샘플을 선택, annotator에게 “이 샘플들은 같은 슬라이스에 속하는가?”라는 이진 질문을 제시한다.
특성 표현 측면에서 저자들은 (1) 원본 텍스트의 TF‑IDF 벡터, (2) 사전 학습된 BERT 기반 임베딩, (3) 모델 내부의 마지막 은닉 상태를 활용한 표현을 비교하였다. 실험 결과, 사전 학습된 언어 모델 임베딩이 가장 풍부한 의미 정보를 제공해 슬라이스 구분에 유리했으며, 특히 고차원 공간에서의 거리 기반 군집화가 효과적이었다.
활성 학습 알고리즘은 크게 (a) 불확실성 기반 (예: 최대 엔트로피, 최소 마진), (b) 대표성 기반 (예: 코어셋, 클러스터 중심 선택), (c) 혼합형 전략으로 구분된다. 논문에서는 특히 불확실성 기반 방법이 적은 라벨링 비용으로도 높은 정확도를 유지한다는 점을 강조한다. 이는 모델이 해당 샘플에 대해 가장 큰 예측 불확실성을 보일 때, 해당 샘플이 아직 정의되지 않은 새로운 오류 슬라이스에 속할 가능성이 높기 때문이다.
실험은 Toxicity Classification 데이터셋을 사용해 인간이 정의한 여러 슬라이스(예: 특정 인종, 성별, 정치적 성향에 대한 편향)를 목표로 수행되었다. 평가 지표는 (1) 슬라이스 탐색 정확도, (2) 라벨링 비용 대비 성능 향상, (3) 기존 베이스라인(무작위 샘플링, 전통적 군집화)과의 비교였다. 결과는 불확실성 기반 활성 학습이 210%의 라벨링 비율로도 8095% 수준의 탐색 정확도를 달성했으며, 베이스라인 대비 10~30%p의 절대적 향상을 보였다.
또한, 저자들은 슬라이스 탐색 과정에서 발생할 수 있는 ‘오버피팅’ 위험을 완화하기 위해 교차 검증 기반의 정밀도-재현율 균형 조정 기법을 도입하였다. 이 기법은 선택된 샘플이 특정 슬라이스에 과도하게 편중되지 않도록 하여, 탐색 결과가 보다 일반화 가능하도록 만든다.
전체적으로 본 논문은 오류 슬라이스를 발견하는 새로운 패러다임을 제시함과 동시에, 실제 시스템에 적용 가능한 실용적인 가이드라인(특성 선택, 활성 학습 알고리즘 선택, 라벨링 예산 설정)을 제공한다. 향후 연구에서는 다중 라벨 슬라이스, 연속형 오류 강도, 그리고 비정형 데이터(이미지, 음성)로의 확장이 기대된다.