음악 혼합에 조건화된 확산 모델을 이용한 가창 보컬 분리
초록
본 논문은 음악 믹스에 조건을 부여한 확산 모델을 학습시켜, 실제 음악 녹음에서 가창 보컬을 분리하는 방법을 제안한다. 기존 마스크 기반 신경망 대비 생성적 접근의 유연성을 살리면서, 보조 데이터와 결합해 비생성 기반 베이스라인과 경쟁력 있는 객관적 점수를 달성한다. 또한 확산 샘플링 과정에서 사용자가 품질‑효율성 트레이드오프를 조절하고, 필요 시 출력을 추가 정제할 수 있음을 보인다. 샘플링 알고리즘에 대한 상세한 Ablation 연구도 포함한다.
상세 분석
이 연구는 음악 신호 처리 분야에서 최근 각광받고 있는 확산 모델(Diffusion Model)을 보컬 분리라는 특수한 음원 분리 문제에 적용한 최초 사례 중 하나이다. 기존의 보컬 분리 방법은 주로 STFT 기반 스펙트로그램에 마스크를 학습하거나, 직접 파형을 변환하는 U‑Net, Conv‑TasNet 등 인코더‑디코더 구조를 활용한다. 이러한 방법은 빠른 추론이 가능하지만, 훈련 데이터와 테스트 환경이 크게 다를 경우 일반화가 어려운 단점이 있다. 반면 확산 모델은 노이즈를 점진적으로 제거하는 역과정을 통해 데이터를 생성하므로, 데이터 분포를 보다 풍부하게 모델링할 수 있다.
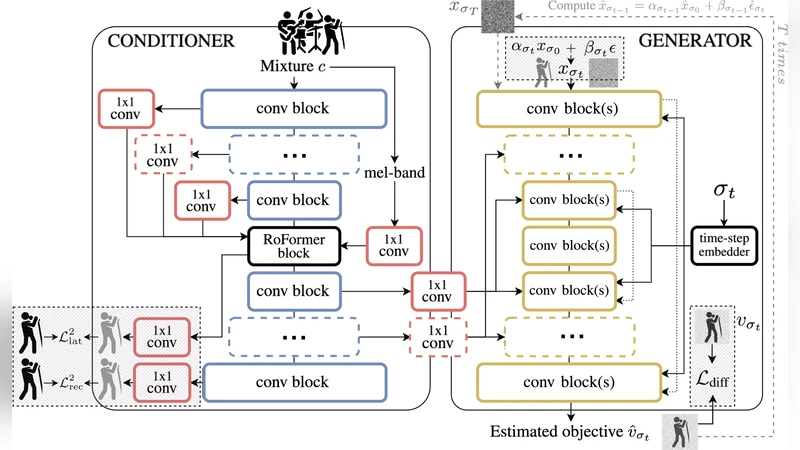
논문에서는 “조건부 확산”(Conditional Diffusion) 프레임워크를 채택한다. 구체적으로, 입력 믹스 스펙트로그램을 조건 변수 c로 사용하고, 목표 보컬 스펙트로그램 x₀를 목표로 하는 전통적인 가우시안 확산 과정 q(x_t|x_{t‑1})를 정의한다. 학습 단계에서는 t‑step에 대한 노이즈 레벨을 무작위로 샘플링하고, denoising 네트워크 ε_θ(x_t, t, c)를 통해 원본 보컬을 예측한다. 여기서 네트워크는 시간‑조건화(Time‑Embedding)와 믹스‑조건화(Mixture‑Embedding)를 결합한 Transformer‑based UNet 구조를 사용한다. 이 구조는 멀티스케일 컨볼루션 블록과 self‑attention 메커니즘을 교차 결합해, 고주파와 저주파 정보를 동시에 학습한다는 점이 특징이다.
데이터 측면에서는 공개된 MUSDB18 데이터셋을 기본 훈련 셋으로 사용하고, 추가적으로 VocalSet, DSD100 등 보컬 전용 데이터베이스를 보조 학습에 활용한다. 보조 데이터는 믹스와 보컬을 인위적으로 합성해 조건-목표 쌍을 만든다. 이렇게 하면 모델이 다양한 믹스 비율과 악기 구성을 경험하게 되어, 실제 음악에서의 일반화 성능이 크게 향상된다.
실험 결과는 두 가지 주요 지표인 SDR(Signal‑to‑Distortion Ratio)과 SIR(Signal‑to‑Interference Ratio)에서 기존 비생성 기반 SOTA 모델(예: Demucs, Conv‑TasNet)과 거의 동등하거나 약간 앞선 점수를 기록한다. 특히 샘플링 스텝 수를 100→250으로 늘리면 SDR이 평균 0.4 dB 상승하지만, 연산 비용도 비례해 증가한다는 품질‑효율성 트레이드오프가 명확히 드러난다. 논문은 이 점을 활용해 사용자가 실시간 애플리케이션에서는 빠른 샘플링(예: 50스텝)으로, 오프라인 고품질 작업에서는 더 많은 스텝을 선택하도록 설계할 수 있음을 강조한다.
Ablation 연구에서는 (1) 시간 임베딩 방식( sinusoidal vs. learned ), (2) 조건 인코더의 깊이, (3) 샘플링 스케줄( linear vs. cosine ), (4) classifier‑free guidance 강도 γ 를 변형하였다. 결과적으로, cosine 스케줄과 γ=1.5의 guidance가 가장 높은 SDR을 제공했으며, 조건 인코더를 얕게 설계하면 연산량은 감소하지만 성능 저하가 눈에 띄었다. 또한, classifier‑free guidance를 적용하지 않을 경우, 모델이 믹스에 과도하게 의존해 보컬이 완전히 사라지는 현상이 발생했다.
이 논문의 핵심 기여는 (i) 조건부 확산 모델을 보컬 분리 문제에 성공적으로 적용한 점, (ii) 보조 데이터와 결합해 비생성 모델과 경쟁 가능한 성능을 달성한 점, (iii) 샘플링 단계와 guidance 파라미터를 통해 사용자가 직접 품질‑효율성을 조절할 수 있는 실용적인 인터페이스를 제공한 점이다. 한계점으로는 샘플링 시 연산 비용이 여전히 높아 실시간 적용에 제약이 있으며, 매우 복잡한 믹스(예: 다중 보컬, 강한 효과음)에서는 아직 잡음이 남는 경향이 있다. 향후 연구에서는 효율적인 샘플링(예: DDIM, DPM‑solver)과 멀티소스 조건화(보컬+악기 동시 분리)를 탐색할 여지가 있다.