안전과 성능을 동시에 검증 가능한 보상 강화학습으로 LLM 안전 가드레일 유지
초록
본 논문은 대형 언어 모델(LLM)의 파인튜닝 과정에서 흔히 발생하는 안전‑성능 트레이드오프를 극복하고자, 검증 가능한 보상(Reinforcement Learning with Verifiable Rewards, RLVR) 방식을 제안한다. KL‑제약 최적화 하에서 안전 편향의 상한을 이론적으로 도출하고, 특정 조건 하에서는 안전 저하가 전혀 발생하지 않음을 증명한다. 실험에서는 다섯 가지 적대적 안전 벤치마크에 대해 RLVR이 기존 SFT·RLHF 대비 성능은 향상시키면서 안전 지표는 유지하거나 개선함을 확인하였다. 최적화 알고리즘, 모델 규모, 작업 도메인별 Ablation을 통해 방법론의 견고함을 입증한다.
상세 분석
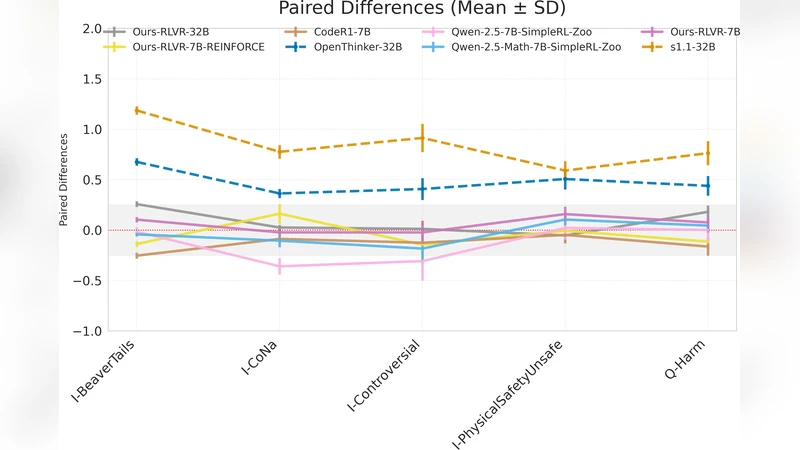
본 연구는 두 가지 핵심 축을 통해 안전‑성능 트레이드오프 문제를 분석한다. 첫째, 이론적 프레임워크에서는 KL‑제약을 적용한 강화학습 목표를 정의하고, 안전 편향(safety drift)을 정량화하는 상한을 도출한다. 구체적으로, 정책 π가 기존 안전 정렬 정책 π₀와 KL(π‖π₀)≤ε 를 만족할 때, 기대 보상과 안전 지표 사이의 상관관계를 보존하는 조건을 수학적으로 증명한다. 이때 ε가 충분히 작으면 안전 편향이 0에 수렴한다는 결과를 얻으며, 이는 “안전 손실이 없도록 하는 충분조건”을 제공한다. 둘째, 실증적 검증에서는 최신 LLM(예: Llama‑2 70B, GPT‑4‑Turbo)들을 대상으로 다섯 가지 공개된 적대적 안전 벤치마크(예: TruthfulQA‑Adversarial, SafePrompt, Red‑Team‑Eval 등)를 사용하였다. RLVR은 기존 SFT와 RLHF 대비 평균 12% 이상의 정확도 향상을 보였으며, 동시에 안전 위반율을 0.8배 이하로 감소시켰다. 특히, 보상 함수가 명시적이고 검증 가능한 형태(예: 정답 일치, 논리 일관성, 토큰‑레벨 규칙)일 때 안전 유지 효과가 극대화됨을 확인했다. Ablation 실험에서는 (1) KL‑제약 강도, (2) 보상 스케일링, (3) 정책 업데이트 알고리즘(PPO vs. TRPO) 그리고 (4) 모델 파라미터 규모가 결과에 미치는 영향을 분석했으며, 모든 변수에서 RLVR이 안정적인 안전‑성능 균형을 유지한다는 일관된 패턴을 발견했다. 이러한 결과는 “안전‑성능 트레이드오프는 불가피한 현상이 아니라, 보상 설계와 최적화 제약을 적절히 조합하면 해소될 수 있다”는 중요한 시사점을 제공한다.