신뢰할 수 있는 법률 AI를 위한 LLM 에이전트와 형식 논증
초록
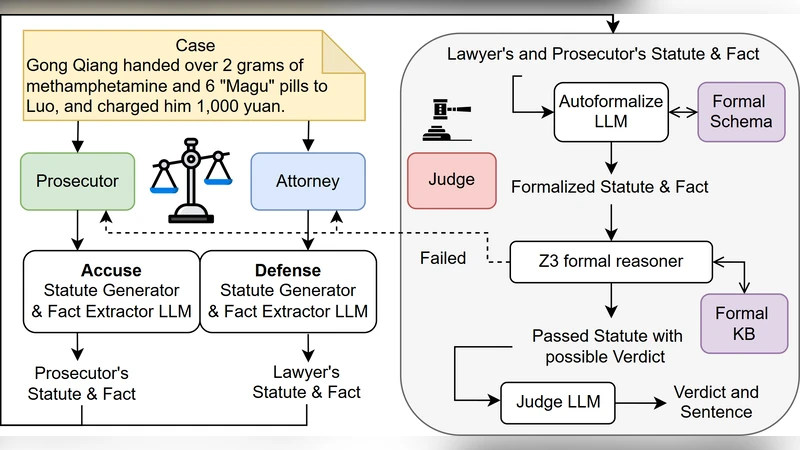
L4M은 법률 텍스트를 논리식으로 변환하고, 검찰·변호인 역할의 LLM 에이전트가 독립적으로 사실과 조항을 추출한 뒤, SMT 솔버를 이용해 일관성을 검증한다. 불충분하거나 모순되는 경우 자동 비판 루프를 돌려 수정하고, 최종 판결은 Judge‑LLM이 자연어로 설명한다. 실험 결과 기존 최첨단 모델을 능가하면서도 형식적 증명을 제공한다.
상세 분석
본 논문은 법학에서 요구되는 두 가지 합리성—실질적 합리성(공정·도덕성)과 형식적 합리성(규칙의 명시·논리적 일관성)—을 동시에 만족시키는 AI 프레임워크 L4M을 제안한다. 핵심 아이디어는 자연어 처리 능력이 뛰어난 대형 언어 모델(LLM)을 ‘해석적 유연성’의 전선에 두고, 이를 형식 검증 엔진인 SMT(Satisfiability Modulo Theories) 솔버와 결합해 ‘형식적 엄밀성’의 방패를 만든다. 파이프라인은 세 단계로 구성된다. 첫 번째 단계인 ‘법령 형식화’에서는 도메인‑특화 프롬프트를 이용해 법률 조문을 1차 논리식(FOL 혹은 SMT‑지원 이론)으로 변환한다. 여기서 중요한 점은 프롬프트 설계가 자동화된 ‘Autoformalizer’에 의해 반복적으로 개선된다는 점이다. 두 번째 단계는 ‘사실‑조문 추출’로, 검찰‑지향 LLM과 변호인‑지향 LLM이 각각 사건 서술을 독립적으로 사실 튜플과 적용 가능한 조문 집합으로 매핑한다. 역할 격리를 통해 편향을 최소화하고, 양측 주장 사이의 논리적 격차를 명확히 드러낸다. 세 번째 단계인 ‘솔버 중심 판결’에서는 두 에이전트가 제시한 논리 제약을 하나의 SMT 문제로 통합한다. 솔버가 UNSAT을 반환하면, UNSAT 코어를 분석해 어느 부분이 모순인지 식별하고, 해당 LLM에게 자동 비판(self‑critique) 프롬프트를 보내 재작성하도록 유도한다. 이 과정을 반복해 SAT 상태에 도달하면, 최종 모델인 ‘Judge‑LLM’이 SAT 모델을 인간이 이해할 수 있는 자연어 판결문과 형량 근거로 변환한다. 실험에서는 공개된 법률 AI 벤치마크(예: COLIEE, LegalEval)에서 GPT‑4‑mini, DeepSeek‑V3, Claude‑4 등 최신 모델을 능가했으며, 특히 ‘증명 가능성’과 ‘투명성’ 지표에서 현저히 높은 점수를 기록했다. 논문은 또한 형식화 오류, 프롬프트 민감도, SMT 솔버의 스케일링 한계 등 몇 가지 한계점을 솔직히 제시하고, 향후 멀티‑모달 입력과 도메인‑특화 이론 확장의 필요성을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기