Transformer가 의미 오류를 감지하는 시점과 위치
초록
본 연구는 phi‑2 인과 언어 모델이 의미적으로 부조화된 문장을 언제, 어느 층에서 인식하는지를 탐색한다. plausibility 판단을 위한 선형 프로브와 표현 차원 분석을 적용해, 하위 1/3 층에서는 구분이 어려우며 중간 층에서 정확도가 급상승하고, 최상위 직전에서 최고에 도달한다는 결과를 얻었다. 또한 위배 정보가 초기에는 표현 공간을 확장시키다 중간 층에서 급격히 축소되는 양상을 보이며, 이는 인간 독해의 구문‑의미 처리 순서와 유사함을 시사한다.
상세 분석
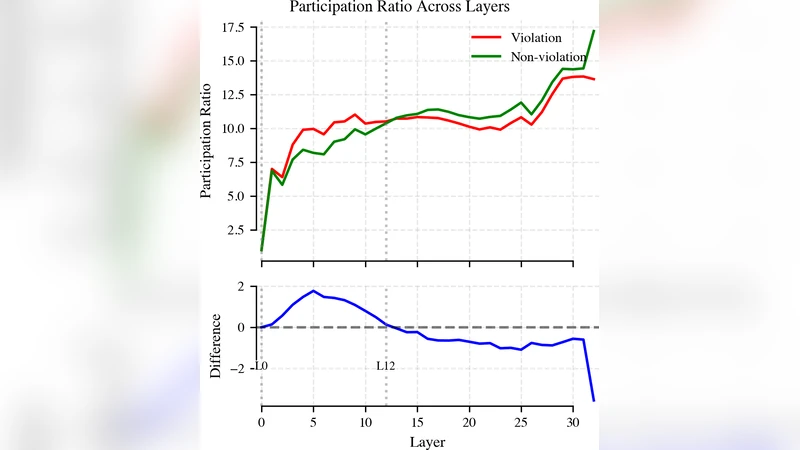
이 논문은 의미적 위배(semantic violation)를 인코딩하는 메커니즘을 파악하기 위해 두 가지 상보적인 탐지 기법을 사용했다. 첫 번째는 각 레이어별 hidden state에 선형 디코더(linear probe)를 학습시켜, plausibility(그럴듯함)와 implausibility(그렇지 않음)를 구분하는 능력을 측정한 것이다. 결과는 모델 하위 1/3 레이어에서는 선형 디코더가 거의 무작위 수준(≈50%)의 정확도를 보였으며, 이는 초기 층이 주로 토큰 수준의 형태소·문법 정보를 처리하고 의미적 통합을 아직 수행하지 않음을 의미한다. 중간 블록(특히 6~9번째 블록)에서 정확도가 급격히 상승해 80% 이상에 도달하고, 최상위 직전 레이어에서 정점에 이른다. 이는 의미적 불일치가 구문 구조가 완전히 해석된 뒤, 즉 “syntactic resolution” 단계 이후에 감지된다는 인간 독해 연구와 일치한다.
두 번째 탐색은 위배가 표현 공간에 미치는 영향을 정량화한 ‘effective dimensionality’ 분석이다. 위배가 발생하면 해당 레이어의 hidden state가 차지하는 차원 수가 일시적으로 증가한다(‘expansion phase’). 이는 모델이 여러 가능한 의미적 해석을 동시에 탐색하는 탐색적 단계로 해석될 수 있다. 이후 중간 층에서 차원 수가 급격히 감소하는 ‘bottleneck’ 현상이 관찰되는데, 이는 의미적 후보들을 압축하고 최종 판단을 내리기 위한 ‘consolidation phase’로 볼 수 있다. 이 두 단계는 서로 보완적으로 작동해, 초기에는 불확실성을 넓게 탐색하고, 이후 빠르게 수렴한다는 점에서 인간의 실시간 언어 처리 모델과 흥미로운 유사성을 보여준다.
또한, phi‑2와 같은 인과 언어 모델이 사전 훈련 과정에서 대규모 텍스트 코퍼스를 통해 암묵적으로 학습한 ‘world knowledge’와 ‘semantic plausibility’를 어떻게 내부 표현에 반영하는지에 대한 실증적 증거를 제공한다. 선형 프로브가 중간 레이어에서 높은 성능을 보인다는 점은, 해당 레이어가 의미적 판단을 위한 핵심 정보 집합을 형성한다는 가설을 뒷받침한다. 반면, 최상위 레이어에서는 약간의 정확도 감소가 관찰되는데, 이는 모델이 최종 토큰 예측을 위해 다시 문맥적 흐름에 초점을 맞추면서 의미적 신호가 약화될 수 있음을 시사한다.
전체적으로 이 연구는 (1) 의미적 위배 감지가 모델 내부에서 단계적으로 진행됨, (2) 중간 레이어가 의미적 통합의 ‘핵심 구간’ 역할을 함, (3) 표현 차원의 확장‑수축 패턴이 의미적 탐색‑수렴 과정을 반영한다는 세 가지 주요 통찰을 제공한다. 이러한 결과는 향후 LLM의 해석 가능성, 오류 진단, 그리고 인간-기계 상호작용 설계에 중요한 시사점을 제공한다.